@[toc]
Linux 内核调度、内存管理与并发的交汇点:membarrier 与 finish_task_switch 深度解析
引言
在现代多核处理器架构下,保证不同CPU核心之间的内存操作顺序和可见性,是操作系统内核必须解决的核心挑战之一。membarrier 系统调用为此而生,它为用户态程序提供了一种强制同步不同核心内存视图的机制。然而,在内核复杂的任务切换路径中,确保 membarrier 的语义被正确实现,揭示了 Linux 内核在性能优化与并发正确性之间精妙的权衡。本文将深入剖析在特定任务切换场景下,finish_task_switch 函数中一段看似不起眼的代码,如何巧妙地解决了因“懒惰TLB”(Lazy TLB)优化而引入的内存同步漏洞,并阐释其背后涉及的内存管理、任务调度与并发控制的联动机制。
一、 问题的根源:membarrier 与内核线程切换
1.1 membarrier 系统调用的契约
membarrier() 系统调用的核心使命是建立一道内存屏障。当一个线程修改了内存,并希望确保运行在其他CPU核心上的线程能够观察到这些修改时,便会调用 membarrier()。内核接收到此请求后,必须采取措施——例如通过处理器间中断(IPI)强制所有目标CPU执行内存屏障指令——来确保在系统调用返回后,各核心的内存视图是一致的。
1.2 内核线程与地址空间带来的挑战
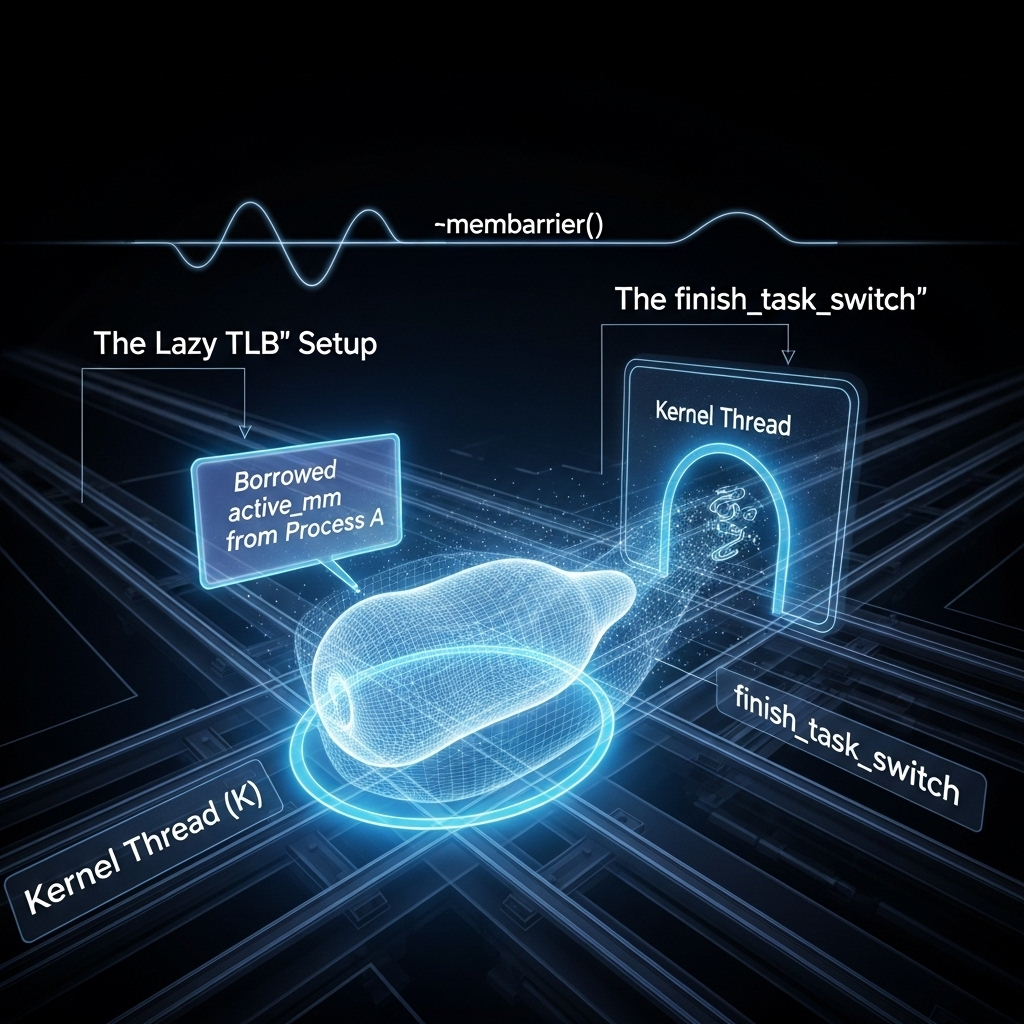
内核线程(Kernel Thread)是一种特殊的任务,它仅在内核空间运行,没有自己的用户地址空间(即 task_struct 中的 mm 字段为 NULL)。为了提升性能,当一个用户进程(User Process)切换到一个内核线程时,内核并不会立即切换地址空间,而是让该内核线程“借用”前一个用户进程的 active_mm。
这种优化引入了一个棘手的同步问题。考虑以下切换路径:
用户进程 A -> 内核线程 K -> 用户进程 B
- A -> K: 进程 A 被换下,内核线程 K 开始运行。
context_switch函数发现 K 没有自己的mm,于是让 K 借用 A 的active_mm。此时CPU硬件层面仍然使用着 A 的页表。 - K -> B: 内核线程 K 被换下,用户进程 B 开始运行。
context_switch发现 B 有自己的mm,于是调用switch_mm将地址空间从 A 的切换到 B 的。
在这个过程中,CPU 使用的地址空间从 A 切换到了 B,但这个切换路径与常规的“用户进程 -> 用户进程”切换不同。如果在此期间,进程 A 或 B 的某个线程调用了 membarrier(),内核的实现机制可能会因CPU当前正在运行一个没有 mm 的内核线程,而做出错误的判断,导致必要的 IPI 同步请求被遗漏,从而破坏了 membarrier 的正确性承诺。
1.3 流程图:潜在的同步漏洞
下图描绘了这种存在同步风险的切换流程。
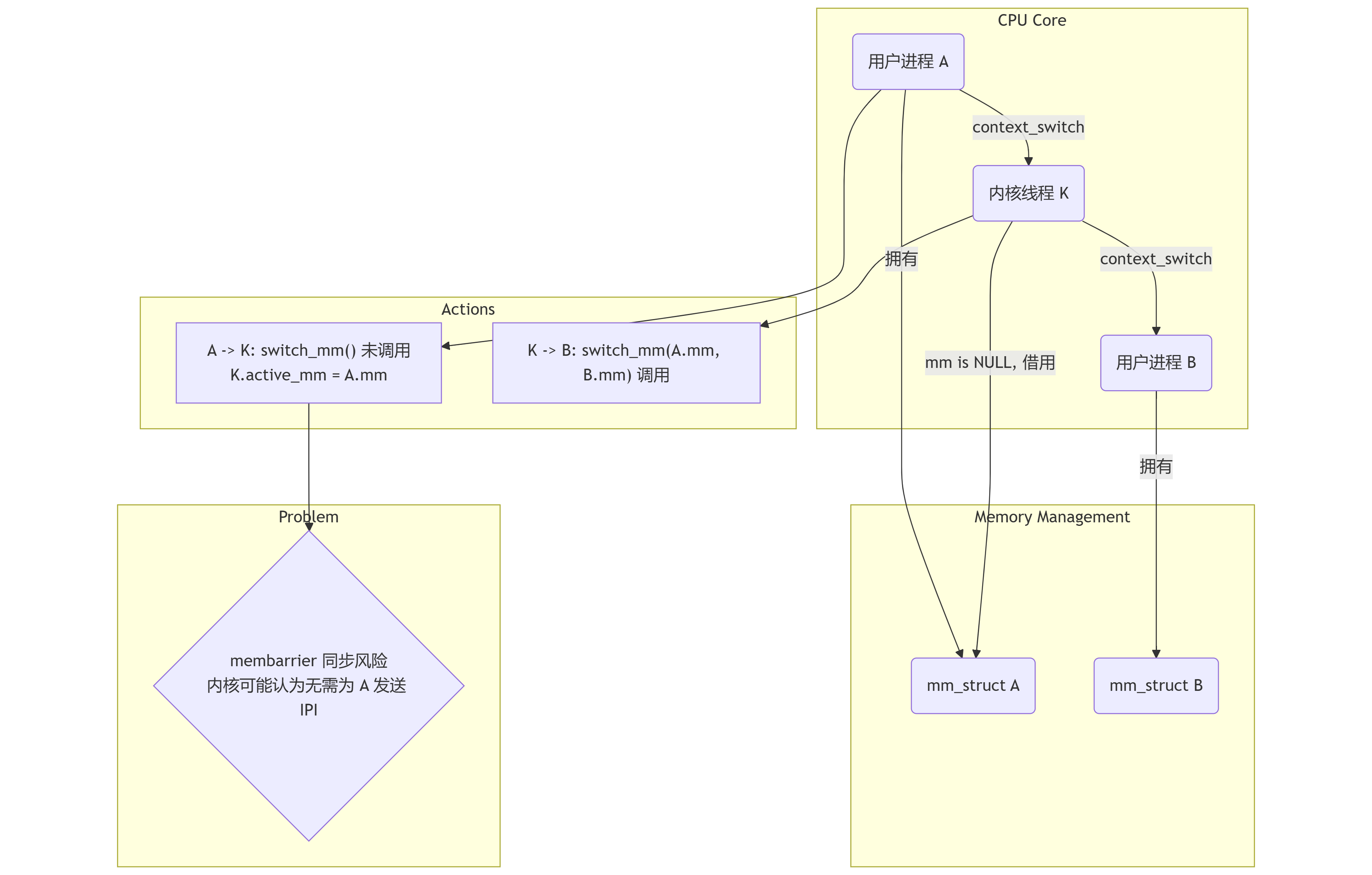
为了修补此漏洞,内核必须确保,即使在没有直接调用switch_mm()的路径上,也存在一个等效的内存屏障。finish_task_switch 函数中的特定代码段正是为此而设。
二、 核心代码段剖析
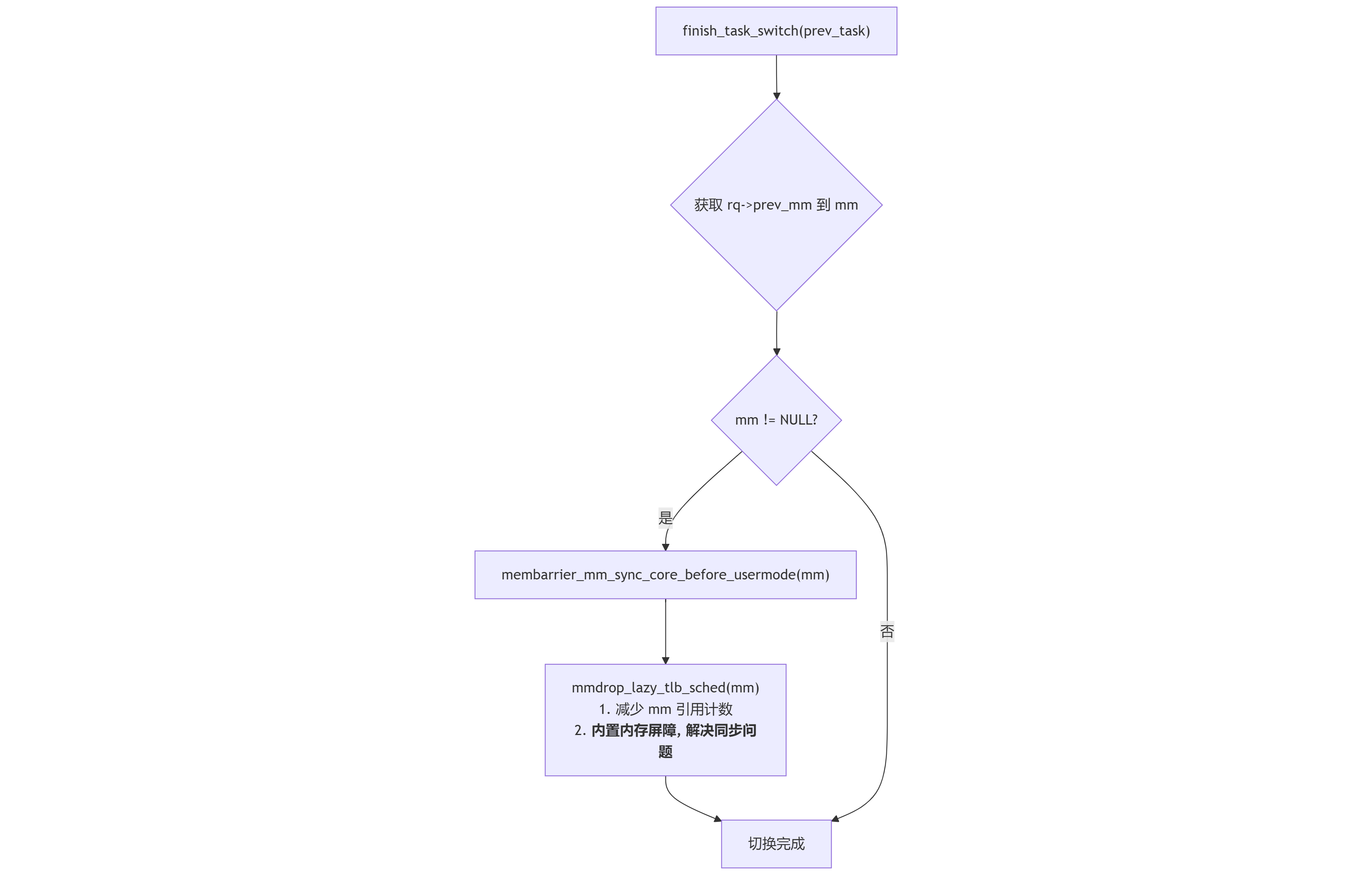
在任务切换的后半部分,finish_task_switch 函数(在调度器锁 rq->lock 释放后执行)包含了解决上述问题的关键逻辑:
1 | /* |
2.1 逻辑触发条件 if (mm)
此处的 mm 变量来自于 finish_task_switch 函数开头从 rq->prev_mm 的赋值。rq->prev_mm 字段仅在一种特定的切换场景下才会被赋值:当一个内核线程(prev->mm 为 NULL)被切换出去,而其 active_mm 不为 NULL 时。这精确地命中了我们之前讨论的 “内核线程 -> 用户进程” 的切换路径。在其他切换路径中,rq->prev_mm 保持为 NULL,因此该代码块不会被执行。
2.2 mmdrop_lazy_tlb_sched(mm) 的双重职责
这个函数是整个机制的核心,它承担了两个重要角色:
资源管理(主要作用): 当内核线程借用一个用户进程的地址空间时,内核会通过
mmgrab()增加该mm_struct的引用计数,以防其被意外释放。当内核线程完成使命被切换走时,必须减少这个引用计数。mmdrop()函数正是用于执行此操作。由于直接在持有调度器锁的context_switch中执行mmdrop()可能因锁竞争导致死锁,内核选择将其延迟到finish_task_switch中执行。并发同步(副作用):
mmdrop()的内部实现包含了一个完整的内存屏障 (smp_mb())。这个内存屏障恰好能满足membarrier(MEMBARRIER_CMD_PRIVATE_EXPEDITED)等命令所要求的同步级别。因此,内核利用了“减少引用计数”这个必须执行的资源管理操作,巧妙地“捎带”完成了membarrier所需的内存屏障,一石二鸟,堵上了同步漏洞。
2.3 membarrier_mm_sync_core_before_usermode(mm)
此函数用于支持更强一致性级别的 membarrier 命令,即 MEMBARRIER_CMD_SYNC_CORE。它确保在当前CPU返回用户模式之前,所有核心的指令执行都已同步,提供了比 smp_mb() 更强的保证。
2.4 流程图:finish_task_switch 的决策逻辑
三、 mm_struct 在不同切换路径下的状态追踪
为了彻底理解该机制,我们必须精确追踪 task->mm 和 task->active_mm 这两个关键指针在不同切换场景下的变化。
task->mm: 指向任务自身拥有的地址空间。用户进程拥有一个mm_struct,而内核线程的mm始终为NULL。task->active_mm: 指向CPU当前实际使用的地址空间。
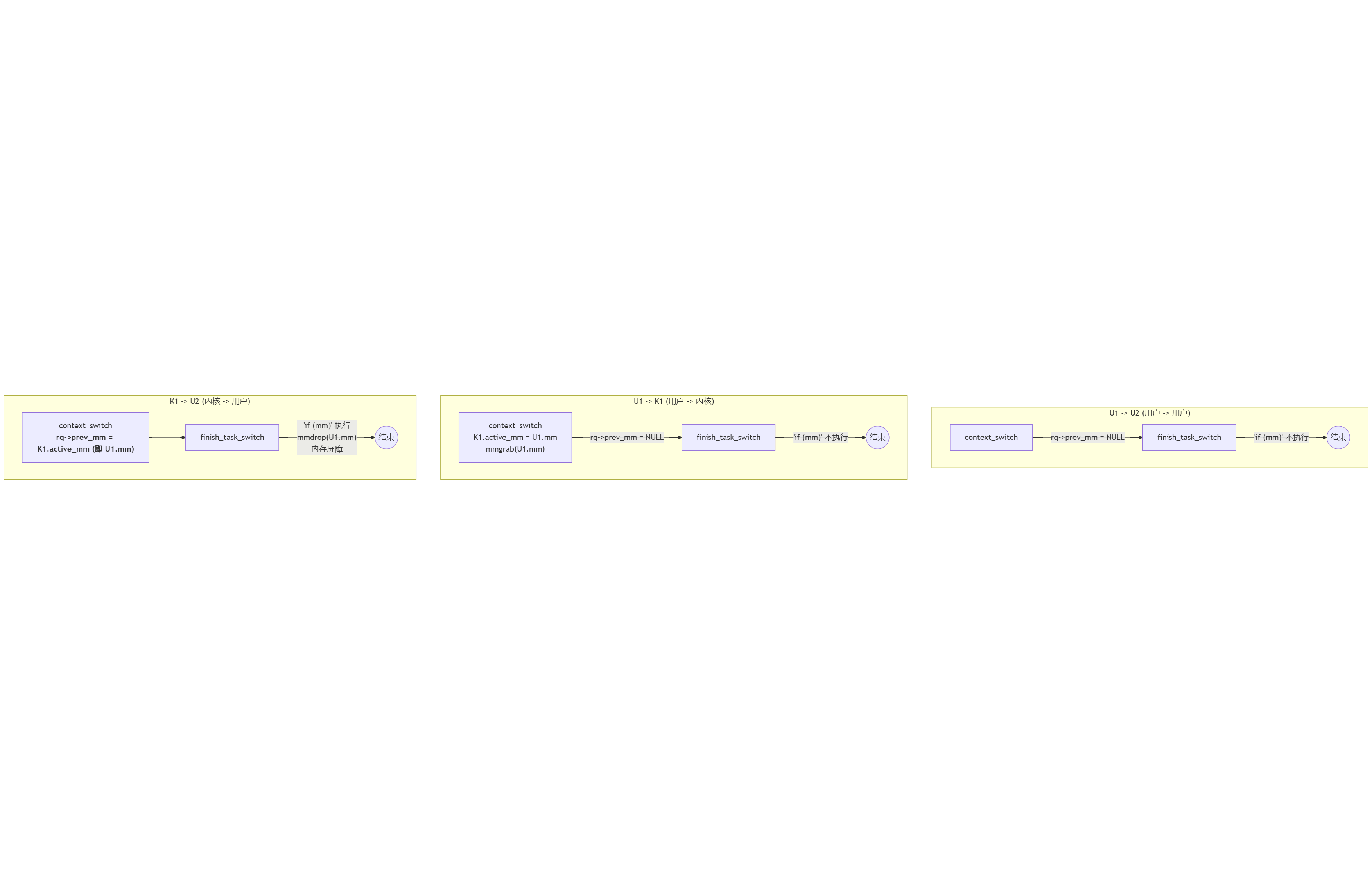
场景1:用户进程 U1 -> 用户进程 U2
context_switch:prev= U1,next= U2。两者mm均不为NULL。- 调用
switch_mm_irqs_off(U1->mm, U2->mm, U2),执行完整的地址空间切换,加载 U2 的页表。 rq->prev_mm不被赋值,保持为NULL。
finish_task_switch:mm变量为NULL。if (mm)代码块不执行。
- 结论: 这种常规切换依赖
switch_mm()自身提供的内存屏障,无需额外处理。
场景2:用户进程 U1 -> 内核线程 K1
context_switch:prev= U1,next= K1。K1 的mm为NULL。- 进入 “Lazy TLB” 模式:
enter_lazy_tlb(U1->active_mm, K1)。 - K1 借用 U1 的地址空间:
K1->active_mm = U1->active_mm。 - 增加 U1 的
mm_struct引用计数:mmgrab_lazy_tlb(U1->active_mm)。 rq->prev_mm不被赋值。
finish_task_switch:mm变量为NULL。if (mm)代码块不执行。
- 结论: 此路径下,地址空间并未实际切换,仅是增加了被借用
mm的引用计数。
场景3:内核线程 K1 -> 用户进程 U2 (K1 正借用 U1 的地址空间)
context_switch:prev= K1,next= U2。K1 的mm为NULL,但K1->active_mm指向 U1 的mm。- 调用
switch_mm_irqs_off(K1->active_mm, U2->mm, U2),地址空间从 U1 的切换到 U2 的。 - 关键步骤:
if (!prev->mm)条件成立,执行rq->prev_mm = K1->active_mm。此时,rq->prev_mm被赋值为指向 U1 的mm_struct。
finish_task_switch:mm变量被赋值为rq->prev_mm(即 U1 的mm_struct)。if (mm)代码块被执行。mmdrop_lazy_tlb_sched(U1->mm)被调用,减少对 U1 地址空间的引用,并附带执行了内存屏障。
- 结论: 正是此路径激活了
finish_task_switch中的补偿逻辑,完成了延迟的资源释放和必要的内存同步。
流程图:三种切换路径对比
四、 结论:精妙的设计协同
Linux 内核中 finish_task_switch 的这段处理逻辑,是内核设计者在追求极致性能、保证系统正确性和避免死锁之间取得精妙平衡的典范。整个机制的设计体现了以下原则:
- 性能优化: “Lazy TLB” 模式避免了在“用户->内核”切换时不必要的 TLB 刷新和地址空间切换开销。
- 资源正确性: 通过
mmgrab/mmdrop的引用计数机制,确保了被借用的mm_struct在使用期间不会被其所有者进程销毁。 - 死锁规避: 将可能产生锁竞争的
mmdrop操作从持有调度器锁的context_switch中剥离,延迟到finish_task_switch中执行,并通过rq->prev_mm字段安全地传递上下文。 - 并发协同: 最终,这个为解决资源管理和死锁问题而设计的“延迟释放”机制,其内在的内存屏障副作用,完美地、且几乎没有额外开销地解决了
membarrier在特殊切换路径下的同步漏洞。
这展示了 Linux 内核设计的深刻智慧:一个操作可以同时服务于多个看似无关的目标,形成一个高效、健壮且逻辑自洽的整体。
 微信
微信- 支付寶









