@[toc]
一次由 C 位域非原子写入引发的状态上报异常
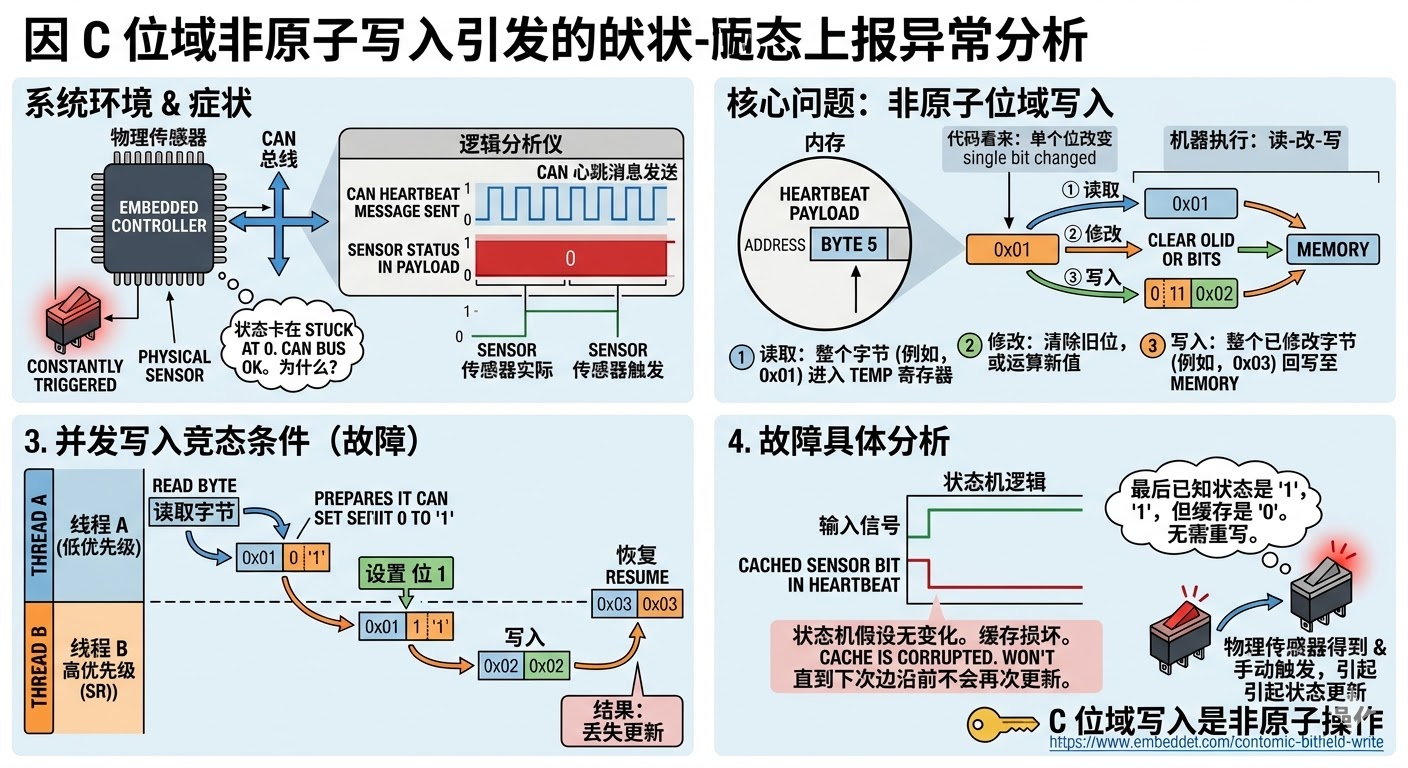
在一套嵌入式控制固件中,出现过一类很典型、但又很容易被忽略的异常:传感器物理状态已经持续触发,心跳报文却长时间仍然上报为 0;重新手动触发一次后,状态又恢复正常。
表面上看,这类问题很像采样抖动、消息队列满、或者 CAN 发送延迟。但沿着发送链路继续深挖后,真正的问题并不在总线,也不在消息队列,而是在 C 语言位域写入不是原子操作 这一点上。
先看现象,不要先怪 CAN
异常表现有几个很强的特征:
- 传感器已经进入触发状态,并且维持了很长时间。
- 心跳报文仍然持续发送,但目标状态位始终是
0。 - 再次手动触发一次传感器后,状态恢复正常。
- 不是“完全没报文”,而是“报文一直有,但某一位一直不对”。
这类现象说明一件事:发送通道本身大概率是通的。如果 CAN 队列、发送线程、或总线仲裁是主因,更常见的表现会是丢帧、延迟、或整帧不发,而不是“整帧一直发,但某一位长期错误”。
因此,排查重点不该先放在“是否发出去”,而应该放在“发出去的那 8 个字节是谁构造的,以及构造时有没有被并发写坏”。
位域写入通常是读改写,不是原子更新
问题的核心在于心跳报文使用了 packed 位域结构。多个状态位被压缩在同一个字节中,例如:
- 某一路传感器状态位
- 5V 电源错误位
- 某些电机失步错误位
这些位在代码里看起来像是独立字段:
1 | heartbeat.Sensor8 = 1; |
但在机器执行层面,这种写法通常不会变成“只改 1 个 bit 的原子写入”,而更接近下面这种读改写流程:
1 | tmp = byte5; |
也就是说,编译器通常会:
- 先读出这个字段所在的整个字节;
- 清掉目标位;
- 填入新值;
- 再把整个字节写回去。
这就是典型的 read-modify-write。
一旦两个上下文同时对同一个字节中的不同位做位域赋值,就有机会出现 丢更新:
- 上下文 A 读到旧值,准备把 bit0 置
1 - 上下文 B 也读到同一个旧值,准备把 bit1 清
0 - A 先写回
- B 再基于旧值写回
最终结果是:A 刚刚写进去的 bit0 被 B 覆盖掉了。
从源码视角看,两个字段互不相关;从内存视角看,它们其实在争抢同一个字节。
多上下文并发写才是问题真正的触发条件
单纯使用位域,并不一定会出错。真正把问题引爆的,是 多个执行上下文同时写同一个心跳对象。
该场景中,至少存在三类写者:
- 传感器滤波逻辑更新传感器状态位;
- 电源状态检查逻辑更新 5V 错误位;
- 电机状态同步逻辑更新失步错误位。
更关键的是,这些写者并不在同一个上下文里顺序执行:
- 有的在高频周期处理中运行;
- 有的在任务线程中运行;
- 有的在另一个状态同步路径中运行。
这样一来,同一个心跳报文对象就成了一个“共享可写结构体”,而且多个字段恰好被 packed 到同一个字节中。只要时序踩中窗口,覆盖就会发生。
问题并不需要高概率复现。只要某一次在恰当的时间发生一次覆盖,就可能把状态推入一个很难自动恢复的错误状态。
“最后一个 1 之后长期变成 0”为什么会出现
这个现象最容易让人误判。
表面看,像是某次状态变化没有发出去。实际上,更合理的解释是:
- 传感器状态已经被确认成
1,并且某一帧心跳也确实正常发出了这个1。 - 随后,另一个上下文对同一心跳对象中的相邻位做了位域写入。
- 由于位域赋值是读改写,目标传感器位被连带覆盖回
0。 - 从这一刻开始,心跳缓存中的该位已经错了。
- 但传感器滤波逻辑内部保存的“上一次状态”仍然是
1。
这会形成一个很关键的分叉:
- 滤波状态机认为当前输入没有变化;
- 心跳缓存里的该位却已经被覆盖成 0。
而滤波逻辑通常只在“检测到变化”时才重写状态位,不会在每个周期都重复刷新。因此,只要物理状态一直保持触发,逻辑层就不会再去补写一次 1。
结果就是:
- 心跳报文还在持续发送;
- 但发送出去的一直是已经被写坏的缓存;
- 错误可以持续很久,直到下一次真实边沿重新触发状态更新。
这也解释了为什么“重新手动触发一下就恢复正常”。
队列快照机制只能保护单帧,保护不了共享状态
很多发送框架会在入队前做一次 payload 快照,例如:
- 调编码函数拿到数据指针;
memcpy到本地队列结构;- 将队列结构入队发送。
这个机制确实有价值,因为它能保证:
- 已经入队的这条消息 不会被后续再修改。
但它保护不了另一件事:
- 共享心跳对象在快照之前或快照之后被别的上下文写坏。
因此,快照机制只能说明“当前这帧一旦入队就是稳定的”,不能说明“全局状态源是稳定的”。
如果共享对象本身已经被并发读改写破坏,那么快照拷走的只是一个稳定的错误值。
这类问题为什么很容易被误判成硬件问题
这类异常有几个特征,天然会把怀疑方向带偏:
- 低概率复现;
- 触发后能持续很久;
- 再次手动触发后又恢复;
- 表面上又像“状态没采上来”。
因此,第一反应通常会是:
- 输入引脚抖动;
- 电平不稳定;
- 采样窗口太窄;
- 消息队列满导致边沿丢失。
这些方向都不是没有可能,但它们解释不了一个关键现象:
某一位长期错误,而整帧持续正常发送。
只要出现这种模式,就必须把“共享状态对象是否被并发改坏”放到更靠前的位置。尤其当代码里用了 packed 位域,而且多个上下文都在直接写它时,这条路径几乎一定要重点检查。
解决思路不在生成代码里,而在写入策略上
这类问题不一定要去修改自动生成的编码文件。更合适的做法,是从架构上减少并发写入共享位域对象的机会。
更稳妥的思路有三类:
1. 不让多个上下文直接写心跳位域对象
把心跳对象视为“发送缓存”,而不是“业务状态源”。
业务状态分别保存在各自的权威源中,发送时统一汇总。
2. 对心跳更新建立单写者模型
由一个固定上下文负责组帧,其余模块只更新各自状态,不直接操作心跳位域。
3. 至少把同一报文的写入与快照发送放进同一保护域
如果短期内无法重构,也需要保证:
- 写心跳字段时不会互相覆盖;
- 取发送快照时不会与写操作并发交错。
无论采用哪一种形式,核心都不是“让位域变成原子”,而是:
不要让多个上下文无保护地对同一个 packed 位域对象做直接写入。
经验教训应该写进编码规范
这类问题的价值,不只在于修复一个现场故障,更在于形成明确的工程约束。
以下规则值得固化:
不要把 packed 位域结构体当作共享状态容器
位域适合描述协议格式,不适合作为多上下文共享状态的直接存储对象。
不要假设位域赋值是原子操作
源码里写的是一个字段,机器层面改的往往是整个字节、甚至整个字。
不要让 ISR、任务线程、周期服务同时直接写同一报文对象
只要多个字段落在同一存储单元,竞态就已经存在。
不要因为“报文在持续发送”就排除共享状态错误
发送稳定,只能证明链路通;不能证明 payload 正确。
这个问题的根因可以总结成一句话
问题并不是传感器没有触发,也不是 CAN 没有发送,而是多个上下文同时对同一个心跳位域对象进行非原子写入,导致状态位被覆盖,最终把系统推入了“缓存错误但状态机不再重写”的异常状态。
这类问题最容易被忽略的点,就是那句看似普通、实际非常关键的话:
C 语言位域写入不是原子操作。
只要这一点没有被明确意识到,任何一个 packed 协议对象都可能在并发环境里变成隐蔽故障源。
 微信
微信- 支付寶








