[toc]
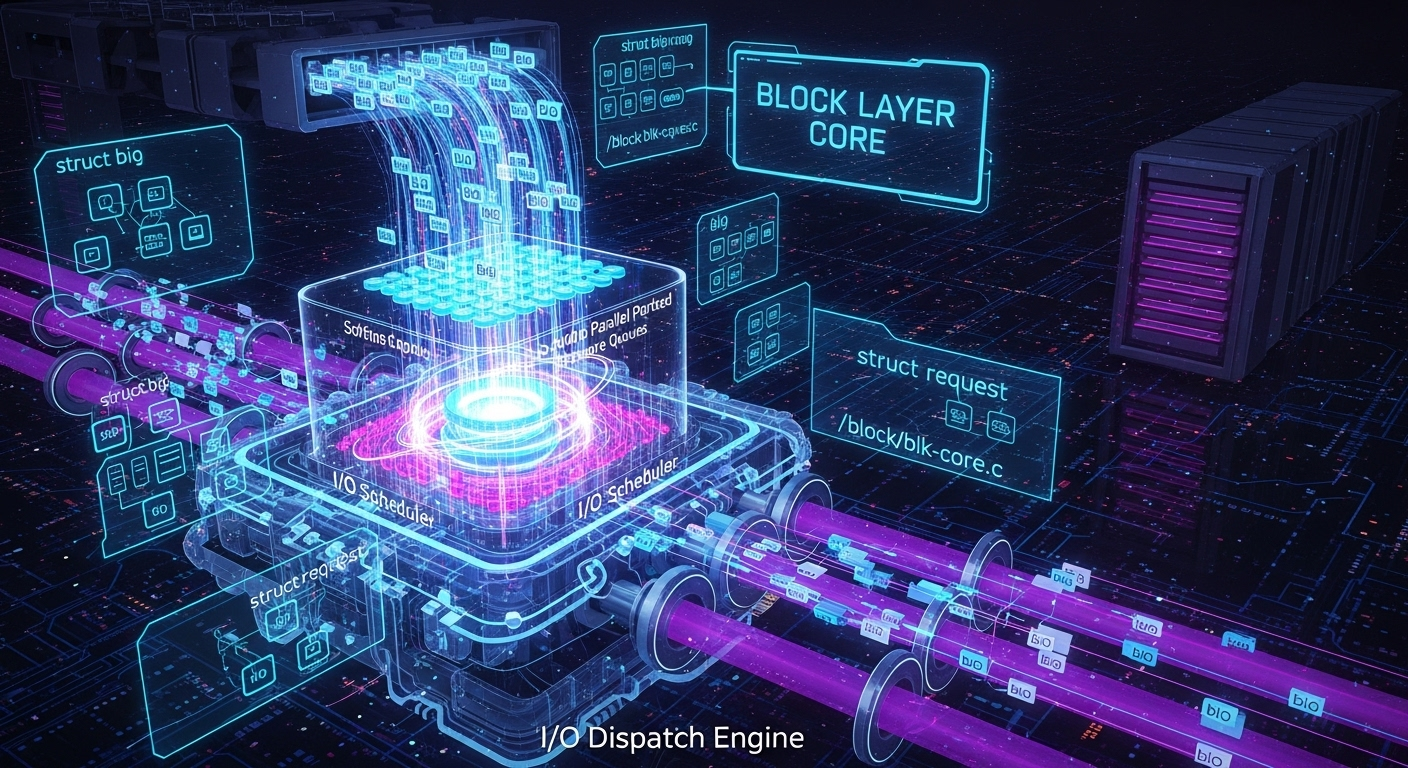
block/blk-core.c 块层核心(Block Layer Core) I/O请求的派发与管理中心
历史与背景
这项技术是为了解决什么特定问题而诞生的?
block/blk-core.c 是Linux块层(Block Layer)的绝对核心。它的诞生是为了解决一个根本性的架构问题:如何在种类繁多的上层I/O请求者(文件系统、裸设备访问、交换等)和五花八门的下层块设备驱动(SATA, SCSI, NVMe等)之间建立一个高效、通用、可扩展的中间层。
这个中间层的核心任务包括:
- 请求抽象与标准化:将来自不同源头的I/O请求(在现代内核中,这些请求被封装在
struct bio中)转换成一个标准的、可供调度和处理的单元(struct request)。 - 请求排队与派发 (Queuing & Dispatch):为每个块设备维护一个请求队列(
struct request_queue),管理等待处理的I/O请求。 - I/O调度 (I/O Scheduling):在将请求发送给硬件之前,通过可插拔的I/O调度器对它们进行排序和合并,以优化磁盘寻道时间(对HDD)或内部并行性(对SSD)。
- 请求合并与拆分 (Merging & Splitting):为了提高效率,将物理上相邻的小I/O请求合并成一个大的请求;反之,将过大的或跨越边界的请求拆分成多个小请求。
如果没有blk-core.c这个核心,每个文件系统都将需要编写与每种块设备驱动直接对话的“胶水代码”,这将导致代码冗余、效率低下且无法维护。
它的发展经历了哪些重要的里程碑或版本迭代?
blk-core.c 的演进史就是Linux I/O栈的演进史:
- 经典的
make_request时代:早期的块层相对简单,所有I/O都通过一个make_request函数进入块层。I/O调度器(如elevator)在这个路径上工作。 bio结构的引入:struct bio的引入是一个重要的进步,它成为了描述I/O请求的通用“语言”,解耦了上层逻辑与块层的内部实现。- 多队列块层 (Multi-Queue Block Layer, blk-mq) (革命性里程碑):随着NVMe等多队列高速SSD的出现,传统的单请求队列模型成为了严重的性能瓶颈。Jens Axboe领导开发了
blk-mq,这是一个全新的、从头设计的块层核心。blk-core.c中的代码被大规模地重构,以支持:- 多硬件队列:直接映射到硬件提供的多个提交/完成队列。
- 软件暂存队列 (Staging Queues):在软件层面为每个CPU核心创建一个队列,极大地减少了锁竞争,提升了扩展性。
blk-core.c现在的核心职责之一就是管理blk-mq的上下文,并将bio分配到正确的CPU软件队列中。
- I/O调度器的演进:伴随着
blk-mq,I/O调度器也演变为mq-deadline,kyber,bfq等mq-aware的版本。
目前该技术的社区活跃度和主流应用情况如何?
blk-core.c 和 blk-mq.c 是Linux内核I/O栈中最活跃、最受关注的部分之一。随着存储硬件的飞速发展(更快的NVMe, ZNS, SMR),块层核心需要不断演进以充分发挥硬件性能。它被所有Linux系统使用,其性能直接决定了整个系统的存储性能。
核心原理与设计
它的核心工作原理是什么?
在现代blk-mq架构下,blk-core.c 的核心工作流程如下:
- I/O提交入口 (
submit_bio):所有上层(如block/fops.c)的I/O请求都以struct bio的形式通过submit_bio进入块层。 - 获取队列和CPU暂存队列:
submit_bio会找到目标块设备的主请求队列(request_queue),然后根据当前CPU ID,获取一个该CPU专属的软件暂存队列(struct blk_mq_ctx)。 - bio到request的转换:
bio会被尝试插入到暂存队列中。在这个过程中,块层会尝试将新的bio与队列中已有的request进行合并(如果它们物理上相邻)。如果无法合并,就会从一个request池中分配一个新的struct request,并将bio的信息填充进去。 - 运行暂存队列 (Running the Queue):当暂存队列中有请求时,或者有其他触发条件时,块层会“运行”这个队列。这意味着暂存队列中的
request会被**派发(dispatch)**到一个或多个硬件派发队列(struct blk_mq_hw_ctx)中。 - I/O调度器介入:在派发过程中,附加在硬件派发队列上的I/O调度器会被调用。调度器会对
request进行排序,以优化性能。 - 驱动程序处理:一旦请求被放入硬件派发队列,设备驱动程序的
queue_rq函数就会被调用。驱动程序负责将request中的信息翻译成硬件命令(如SATA的NCQ命令,或NVMe的提交队列条目),并将其发送给硬件。 - 中断处理与完成:当硬件完成I/O操作后,会产生一个中断。中断处理程序最终会调用
blk_mq_complete_request()等函数,来标记request已完成,并通知上层调用者。
它的主要优势体现在哪些方面?
- 高性能与高扩展性:
blk-mq架构通过per-CPU队列和直接映射硬件队列,极大地减少了锁竞争,使得Linux能够充分利用现代多核CPU和高速多队列SSD的性能。 - 模块化与灵活性:可插拔的I/O调度器设计,使得系统可以根据硬件类型(HDD vs SSD)和工作负载选择最合适的调度策略。
- 通用性:为所有类型的块设备提供了统一的管理框架。
它存在哪些已知的劣势、局-限性或在特定场景下的不适用性?
- 复杂性:
blk-mq的内部逻辑非常复杂,涉及多层队列、CPU亲和性、中断处理等,使得调试和性能分析变得困难。 - 对慢速设备可能的开销:对于传统的、低速的单队列设备(如一些USB设备),
blk-mq的复杂框架可能会带来比传统单队列模型略高的开销。尽管内核有优化,但这仍是一个理论上的考量。
使用场景
在哪些具体的业务或技术场景下,它是首选解决方案?
blk-core.c 是所有块设备I/O的必经之路,因此它没有“可选”的场景。以下场景的性能表现高度依赖于blk-core.c及其blk-mq架构的效率:
- 高性能数据库:OLTP数据库产生大量随机、小块I/O,
blk-mq的低延迟路径对于提升TPS(每秒事务数)至关重要。 - 大数据与分析:这些工作负载通常涉及大量顺序读写,
blk-core.c的请求合并能力和I/O调度器可以有效地将这些流式I/O聚合,提升吞吐量。 - 虚拟化与云计算:在单个物理主机上运行大量虚拟机或容器时,存储I/O会从多个源头汇集而来。
blk-mq的高扩展性确保了I/O性能不会因为高并发而崩溃。
是否有不推荐使用该技术的场景?为什么?
不能“不使用”该技术。但是,对于某些非块设备的存储,会绕过这个路径:
- 网络文件系统 (NFS, CIFS):这些文件系统的I/O请求会直接进入网络栈,而不是块层。
- 某些用户空间存储驱动 (SPDK, DPDK):为了追求极致的低延迟,这些框架会完全绕过内核(包括块层),在用户空间直接轮询硬件(polling)来处理I/O。这是一种特殊的高性能计算场景,牺牲了通用性换取性能。
对比分析
请将其 与 其他相似技术 进行详细对比。
blk-core.c (块层核心) vs. block/fops.c (块设备文件操作)
| 特性 | blk-core.c (块层核心) |
block/fops.c (块设备文件操作) |
|---|---|---|
| 角色定位 | I/O处理引擎。是块层内部的、对上层透明的请求处理和调度中心。 | 用户空间接口。是连接用户空间和块层的“门面”或“适配器”。 |
| 工作在哪个层次 | 块层内部。处理的是内核数据结构struct bio和struct request。 |
VFS与块层之间。负责将来自用户空间的read/write系统调用翻译成struct bio。 |
| 主要职责 | 请求排队、调度、合并、拆分、派发给驱动。 | 实现file_operations接口,处理open, read, write, ioctl等。 |
| 关系 | 下游。block/fops.c是blk-core.c的众多“客户”之一。fops.c通过调用submit_bio()将工作交给了blk-core.c。 |
上游。为blk-core.c提供了来自裸设备访问的I/O源。 |
blk-core.c (块层) vs. SCSI/NVMe子系统
| 特性 | blk-core.c (块层核心) |
SCSI/NVMe子系统 |
|---|---|---|
| 抽象层次 | 通用。提供的是与具体硬件协议无关的、统一的块I/O模型(request)。 |
特定。实现了具体的存储协议(如SCSI命令集,或NVMe的提交/完成队列规范)。 |
| 主要职责 | 管理I/O流,优化性能。 | 将块层的通用request结构翻译成特定协议的命令,并与硬件交互。 |
| 关系 | 上层。blk-core.c将经过调度和处理的request派发给下层的协议驱动。 |
下层。作为blk-core.c的“执行者”,负责实现与具体硬件的通信。 |
I/O 繁忙时间统计更新: update_io_ticks
本代码片段定义了内核块设备层中一个核心的统计更新函数 update_io_ticks。其主要功能是以一种高效、无锁(lock-free)的方式,精确地计算并累加一个块设备处于“繁忙”状态(即至少有一个 I/O 请求在处理中)的总时长。这个函数是 /proc/diskstats 中第13个字段(加权 I/O 毫秒数)的数据来源,对于上层 I/O 性能监控工具(如 iostat)至关重要。
实现原理分析
此函数的实现是 Linux 内核中一个精妙的、用于高并发环境的无锁编程范例。它不使用传统的自旋锁来保护统计数据,而是采用了一种基于原子操作的乐观更新(optimistic update)策略。
时间戳与原子更新 (
bd_stamp&try_cmpxchg):- 每个块设备结构体中都有一个时间戳成员
bd_stamp。这个时间戳记录了上一次本函数成功更新io_ticks的时刻(以jiffies计)。 - 函数的核心是
try_cmpxchg(&part->bd_stamp, &stamp, now)。这是一个原子的“比较并交换”(Compare-And-Swap)操作。 - 算法流程:
a. 首先,通过READ_ONCE无锁地读取当前的bd_stamp值到局部变量stamp。
b. 然后,try_cmpxchg尝试将part->bd_stamp的值更新为当前时间now,但前提条件是part->bd_stamp的值仍然等于之前读取的stamp。
c. 如果try_cmpxchg成功,意味着从stamp到now这段时间内,没有其他任何任务(或其他 CPU 上的任务)成功更新过这个时间戳。当前任务便“赢得”了更新的权利,于是它将时间差now - stamp累加到io_ticks统计中。
d. 如果try_cmpxchg失败,说明就在READ_ONCE之后,另一个任务已经抢先更新了bd_stamp。此时,当前任务就简单地放弃本次更新。这样做是正确的,因为那个抢先的任务已经把到它那个时间点的繁忙时长计算过了,避免了重复计算。
- 每个块设备结构体中都有一个时间戳成员
更新条件 (
end || bdev_count_inflight(part)):try_cmpxchg成功后,还需要满足一个条件才能真正累加io_ticks。bdev_count_inflight(part)检查设备当前是否仍有在途 I/O。如果 > 0,说明设备仍然是繁忙的,因此从stamp到now这段时间理应被计入繁忙时长。end标志位是一个特殊情况。当最后一个在途 I/O 完成时,bdev_count_inflight会变为 0。如果不做处理,now - stamp这最后一段繁忙时间将不会被计入。因此,处理最后一个 I/O 完成的调用者会设置end = true来强制执行这最后一次的累加,确保统计的完整性。
分层统计 (
goto again):update_io_ticks的设计考虑了磁盘和分区的层级关系。- 当对一个分区(
bdev_is_partition为真)调用此函数后,它会通过bdev_whole(part)找到该分区所属的整个磁盘设备,然后使用goto again重新对整个磁盘设备执行一遍完全相同的逻辑。 - 这确保了对分区的 I/O 活动,其繁忙时间不仅会累加到分区自身的统计中,也会被正确地累加到其父磁盘的统计中。
代码分析
1 | /** |
请求队列的创建与初始化 (blk_alloc_queue)
核心功能
blk_alloc_queue 是一个核心工厂函数,其唯一职责是分配并全面初始化一个 struct request_queue 对象。这个对象是块设备驱动与内核块设备层之间进行 I/O 交互的核心数据结构。它不仅是一个请求的容器,更是一个集成了锁、定时器、引用计数、I/O 调度器接口、统计信息和硬件限制等众多子系统的复杂实体。任何一个想要接收 I/O 请求的块设备,都必须拥有一个由该函数创建的请求队列。
实现原理分析
并发管理中心:
request_queue是一个高度并发的数据结构,它可能同时被多个上下文访问:- 用户进程通过系统调用提交 I/O 请求(进程上下文)。
- 内核线程(如
kblockd)处理工作(进程上下文)。 - 硬件中断处理程序报告 I/O 完成(中断上下文)。
- 定时器中断处理请求超时(中断上下文)。
因此,blk_alloc_queue的一个主要任务是初始化各种锁来保护队列的内部状态。它使用了多种锁,体现了精细化锁的设计思想:sysfs_lock用于保护对 sysfs 属性的访问,elevator_lock用于保护 I/O 调度器(elevator)的数据结构,而queue_lock(自旋锁) 则用于保护队列本身的核心数据路径。
高级引用计数 (
percpu_ref): 队列的生命周期管理使用了一种高级的、为高性能而设计的percpu_ref引用计数器。与简单的原子引用计数(atomic_t)不同,percpu_ref允许每个 CPU 在本地、无锁地增加引用计数,这极大地降低了在 I/O 密集型场景下的锁竞争。当需要销毁队列时,内核会“杀死”这个percpu_ref,此时它会等待所有 CPU 上的本地引用计数都归零后,再调用注册的回调函数blk_queue_usage_counter_release。这是一种高效且健壮的,用于管理高并发对象生命周期的模式。两阶段超时处理: 请求超时处理被设计为两阶段过程以降低中断上下文的负担。
a.timer_setup(&q->timeout, blk_rq_timed_out_timer, 0): 注册一个标准的内核定时器。当定时器到期时,硬件中断会触发blk_rq_timed_out_timer函数。
b.kblockd_schedule_work(&q->timeout_work): 在定时器中断处理函数中,唯一做的事情就是调度一个工作(work_struct)。它不会执行任何复杂的逻辑。
c.blk_timeout_work: 实际的、可能很复杂的超时处理逻辑在这个工作队列函数中执行。
这种模式是内核的标准实践:在(硬)中断上下文中只做最少的工作,将耗时或可能休眠的操作转移到(软中断或)进程上下文(工作队列)中去执行。硬件能力描述 (
queue_limits): 函数接收一个struct queue_limits参数。这个结构体是驱动程序向块设备层描述其底层硬件能力的“说明书”。驱动在其中填写诸如最大单次传输字节数、逻辑块大小、对齐要求、是否支持DISCARD等信息。blk_alloc_queue将这份说明书拷贝到队列的limits成员中,块设备层后续会依据这些限制来对上层发来的 I/O 请求进行必要的拆分或合并。
源码及逐行注释
1 | /** |
blk_try_enter_queue blk_queue_enter 队列进入引用获取与冻结等待门控
作用与实现要点
- 进入队列的第一道门:先尝试把
q->q_usage_counter引用计数加一;只有队列仍“存活”时才允许后续提交/分配请求,避免队列正在销毁时又进新 I/O。 - PM-only 门控:队列处于
pm_only时只允许 PM 路径进入;同时若运行时电源处于挂起态(RPM_SUSPENDED),即便走 PM 也会拒绝进入,避免在挂起/冻结窗口里卡住或产生不期望的唤醒链路。 - 等待与退出条件:非 NOWAIT 路径在进入失败后睡眠等待
mq_freeze_wq,直到“解冻且 PM 条件允许”或“队列 dying”;一旦 dying,直接返回-ENODEV。 - 读序保证:
smp_rmb()用来把“看到 q_usage_counter 已 dead”与“看到 freeze_depth / dying 状态”按顺序约束,避免读重排序导致等待条件永远观察不到变化而睡死。 - lockdep 标注:末尾对
q_lockdep_map的 acquire/release 仅用于 lockdep 建模,建立“进入队列”与队列锁的依赖关系,运行时不真正持有该 rwsem。
blk_try_enter_queue 尝试进入队列并做 PM-only 访问门控
1 | /** |
blk_queue_enter 阻塞或 NOWAIT 方式进入队列并处理冻结/销毁
1 |
|
 微信
微信- 支付寶










