[toc]
block/kyber-iosched.c Kyber I/O调度器 基于延迟目标的现代I/O调度器
历史与背景
这项技术是为了解决什么特定问题而诞生的?
Kyber I/O调度器的诞生是为了解决一个在超高速存储设备(如NVMe SSD)上日益凸显的问题:传统的I/O调度器(如Deadline, CFQ)主要优化吞吐量或公平性,但在现代硬件上,软件排队本身成为了延迟的主要来源。
当存储设备快到可以在微秒级完成I/O时,如果内核软件栈中排队了过多的请求(即高队列深度),那么一个新到来的、关键的读请求可能会排在几百个已提交的请求之后,导致其总延迟变得很高。Kyber的设计目标是转变优化思路:不再间接地追求低延迟,而是直接将延迟作为一个可配置的、必须达成的目标。
它旨在回答这样一个问题:我们如何向设备施加恰到好处的压力,既能获得足够的吞吐量,又能确保绝大多数请求的完成延迟都低于一个预设的目标值?
它的发展经历了哪些重要的里程碑或版本迭代?
- Facebook (Meta) 的创新:Kyber最初由Facebook的工程师开发,旨在解决其大规模数据中心中,高速闪存设备上数据库等延迟敏感型应用的性能可预测性问题。
- 为
blk-mq而生:它从一开始就是为现代多队列块层(blk-mq)设计的,充分利用了per-cpu队列和多硬件队列的优势。 - 合入主线内核:在经过社区的审查和改进后,Kyber在Linux 4.12内核版本中被正式合入,成为与
mq-deadline和bfq并列的标准mq调度器选项之一。
目前该技术的社区活跃度和主流应用情况如何?
Kyber是一个成熟且稳定的mq调度器。虽然它不是大多数发行版的默认选项,但在特定领域,它是一个非常重要的性能工具:
- 数据中心和云计算:在对服务等级协议(SLA)中的P99/P99.9尾延迟(tail latency)有严格要求的环境中,Kyber是一个强大的工具。
- 性能调优:对于运行在高速NVMe上的延迟敏感型应用,系统管理员和SRE(网站可靠性工程师)会考虑切换到Kyber并调整其延迟目标,以获得稳定且可预测的I/O性能。
核心原理与设计
它的核心工作原理是什么?
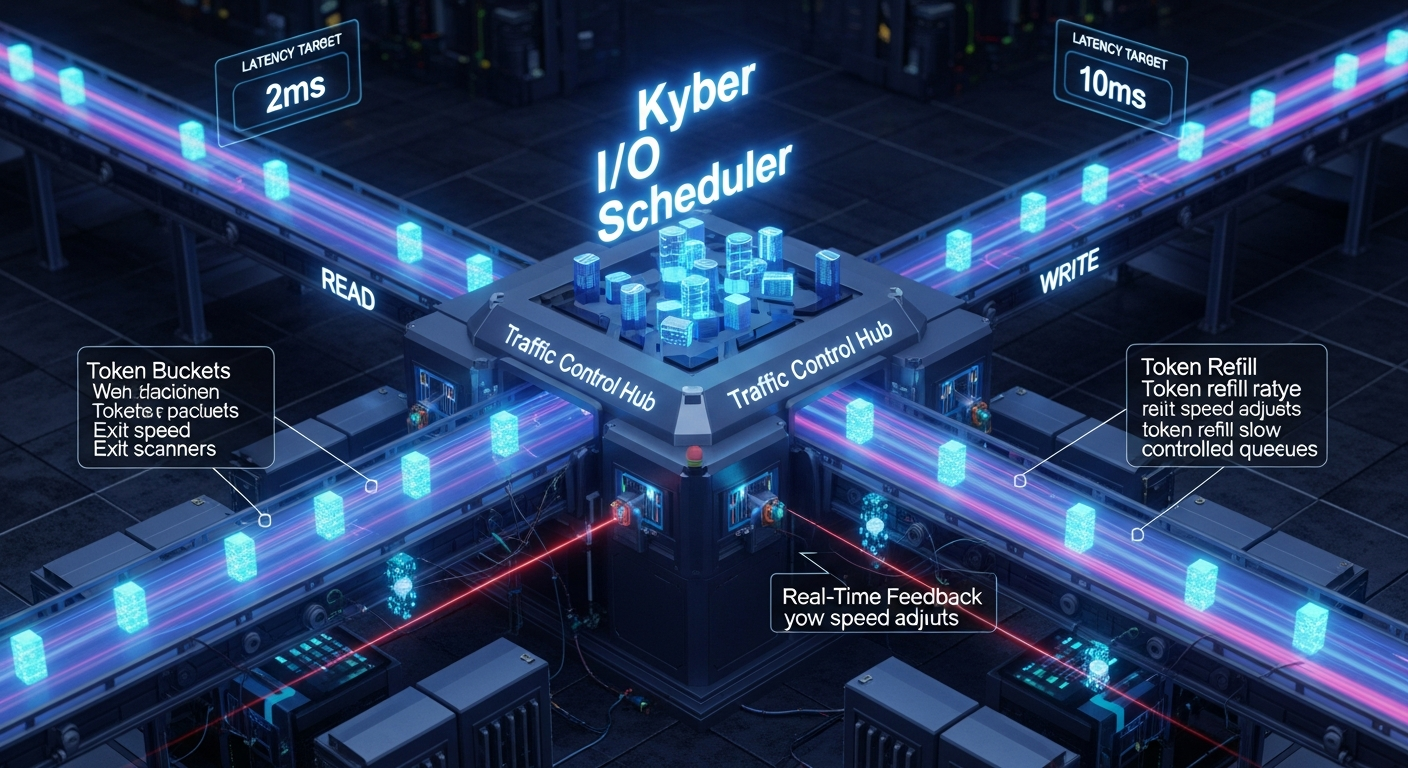
Kyber的核心是一个基于**反馈循环(Feedback Loop)的令牌桶(Token Bucket)**算法,它通过控制I/O请求的派发速率来主动管理设备队列深度,从而将延迟维持在目标水平。
- 延迟目标(Latency Target):管理员为读和写操作分别配置一个期望的完成延迟(例如,读操作2毫秒,写操作10毫-秒)。这是Kyber所有决策的基准。
- 延迟测量:Kyber会持续测量已完成请求的实际端到端延迟(从请求提交到完成的全部时间)。
- 令牌(Tokens):一个进程需要获得一个“令牌”才能将其请求派发到硬件队列。令牌的数量是有限的。
- 动态调整:这是Kyber的“智能”所在。它会定期比较实际测量延迟和预设的延迟目标:
- 如果
实际延迟 < 目标延迟:说明设备还有余力。Kyber会增加令牌桶的容量或发放速率,允许更多的请求被同时派发到硬件,从而提高队列深度和吞öt量。 - 如果
实际延迟 > 目标延迟:说明设备开始过载,延迟超标。Kyber会减少令牌桶的容量或发放速率,主动限制(节流)新请求的派发,从而降低队列深度,让设备有时间“喘口气”,使延迟回归到目标值以下。
- 如果
通过这个持续的“测量-比较-调整”循环,Kyber能够动态地找到一个特定硬件和工作负载下的“最佳操作点”(sweet spot),在该点上,延迟目标得以满足,同时吞öt量也得到了尽可能的保证。
它的主要优势体现在哪些方面?
- 可预测的性能:其最核心的优势是提供了可预测的I/O延迟,尤其是尾延迟,这对于有严格SLA要求的服务至关重要。
- 自适应性:能够根据实际工作负载和硬件响应的变化,自动调整队列深度,无需人工干预。
- 防止过载:通过主动节流,有效防止了因提交过多请求而导致的设备性能悬崖式下跌。
- 简单配置:相比于BFQ复杂的权重和启发式规则,Kyber的核心可调参数就是两个直观的延迟目标值。
它存在哪些已知的劣势、局限性或在特定场景下的不适用性?
- 吞吐量优先场景:Kyber的首要目标是保延迟,这有时会以牺牲峰值吞吐量为代价。如果一个任务只关心尽可能快地完成大量数据传输(如备份),而不关心延迟,那么
none调度器可能性能更高。 - 不关注公平性:与BFQ不同,Kyber不提供进程间的I/O公平性保证。它主要关注整个设备的总体延迟表现。
- 配置依赖:虽然是自适应的,但初始的延迟目标设置仍然很重要。一个不切实际的低目标可能导致吞öt量严重不足,而一个过高的目标则使其失去了延迟控制的意义。
- 不适合慢速设备:在HDD上,其固有的高延迟和巨大的延迟方差使得Kyber的精细控制模型难以有效工作。
使用场景
在哪些具体的业务或技术场景下,它是首选解决方案?
- 延迟敏感型数据库:运行在高速NVMe SSD上的在线事务处理(OLTP)数据库,用户请求的响应时间直接与磁盘读延迟挂钩。
- 云存储后端:为云硬盘(如EBS)提供服务时,需要保证不同租户的I/O延迟在一个可预测的范围内。
- 实时数据分析平台:需要从快速存储中稳定地读取数据流进行处理的应用。
- 任何对尾延迟敏感的服务:例如,确保99.9%的用户API请求在特定毫秒内完成,其中存储I/O是关键路径。
是否有不推荐使用该技术的场景?为什么?
- 桌面系统:桌面环境更需要BFQ提供的交互式公平性,以确保UI响应不会被后台的文件索引或下载任务卡住。Kyber不提供这种进程级的公平性。
- 纯吞吐量批处理:对于视频转码、科学计算数据处理、大规模备份等任务,目标是最大化数据传输速度。此时,延迟并不重要,使用
none调度器来消除软件开销通常是最佳选择。 - 机械硬盘(HDD):HDD的物理特性决定了
mq-deadline或bfq这类考虑寻道的调度器是更合适的选择。
对比分析
请将其 与 其他相似技术 进行详细对比。
| 特性 | kyber | mq-deadline | bfq (Budget Fair Queueing) | none |
|---|---|---|---|---|
| 核心原理 | 基于延迟目标的反馈控制 | 截止时间 + LBA排序 | 复杂的预算和权重,为每个进程创建队列 | 简单的FIFO,无重排 |
| CPU开销 | 中等 | 低 | 高 | 最低 |
| 主要目标 | 可预测的I/O延迟 | 平衡吞吐量与延迟 | 公平性和交互性 | 最大化IOPS/吞吐量,最低延迟 |
| 最佳适用硬件 | 高速NVMe/SATA SSD | SATA SSD, HDD, 企业级SSD | HDD, SATA SSD, 桌面环境 | 超高速NVMe SSD |
| cgroups I/O控制 | 否 | 否 | 是 | 否 |
| 关键可调参数 | read_lat_nsec, write_lat_nsec |
read_expire, write_expire |
众多启发式参数 | 无 |
Kyber I/O 调度器模块:定义与注册
本代码片段展示了 Kyber I/O 调度器在 Linux 内核中的定义和注册过程。其核心功能是:通过填充一个 elevator_type 结构体(kyber_sched),将 Kyber 调度算法的所有核心操作(如请求插入、分发、延迟估算等)以函数指针的形式封装起来,并在模块加载时 (kyber_init),将这个完整的调度器“插件”注册到内核的块设备 I/O 调度框架中,使其成为一个可供系统选择和使用的 I/O 调度策略。
实现原理分析
此代码是内核 I/O 调度器“电梯”框架中一个具体调度策略的实现范例。它本身不包含算法的执行逻辑,而是以一种声明式的方式,向块设备层“描述”了 Kyber 调度器的全部行为。
struct elevator_type:调度器的蓝图:kyber_sched结构体是整个调度器的核心定义。它像一个“虚函数表”,将抽象的调度操作映射到具体的实现函数。.ops: 这是最重要的成员,它是一个包含了十几个函数指针的elevator_ops结构。每个函数指针都对应一个 I/O 调度过程中的关键节点:insert_requests: 当新的 I/O 请求从上层传来时,此函数被调用,负责将请求放入 Kyber 的内部队列。dispatch_request: 当设备可以接受新的 I/O 请求时,此函数被调用,负责根据 Kyber 的延迟目标(latency target)和令牌桶(token bucket)算法,从其队列中选择一个“最佳”的请求分发给设备驱动。completed_request: 请求完成后被调用,这是 Kyber 算法的核心之一,用于测量实际的完成延迟,并动态调整其内部的调度参数。init_sched,exit_sched: 分别在调度器为一个设备实例化和销毁时被调用,用于分配和释放私有数据。
.elevator_name: “kyber”,是调度器的唯一标识符,用户空间可以通过这个名字来选择它。.elevator_owner:THIS_MODULE,将此调度器与当前内核模块绑定,用于正确的引用计数管理。
模块化注册与注销:
kyber_init函数在模块加载时被调用。它只做一件事:调用elv_register(&kyber_sched)。这个函数会将kyber_sched结构体添加到一个全局的调度器类型列表中,使其对系统可见和可用。kyber_exit函数在模块卸载时被调用。它对称地调用elv_unregister(&kyber_sched),将调度器从全局列表中移除,并确保所有正在使用此调度器的设备都能安全地切换到其他调度器。- 这种
register/unregister的模式是内核中实现可插拔子系统(如文件系统、调度器、网络协议)的标准方法。
代码分析
1 | // 定义一个 elevator_type 结构体,用于向块层描述 kyber 调度器。 |
 微信
微信- 支付寶









