[TOC]
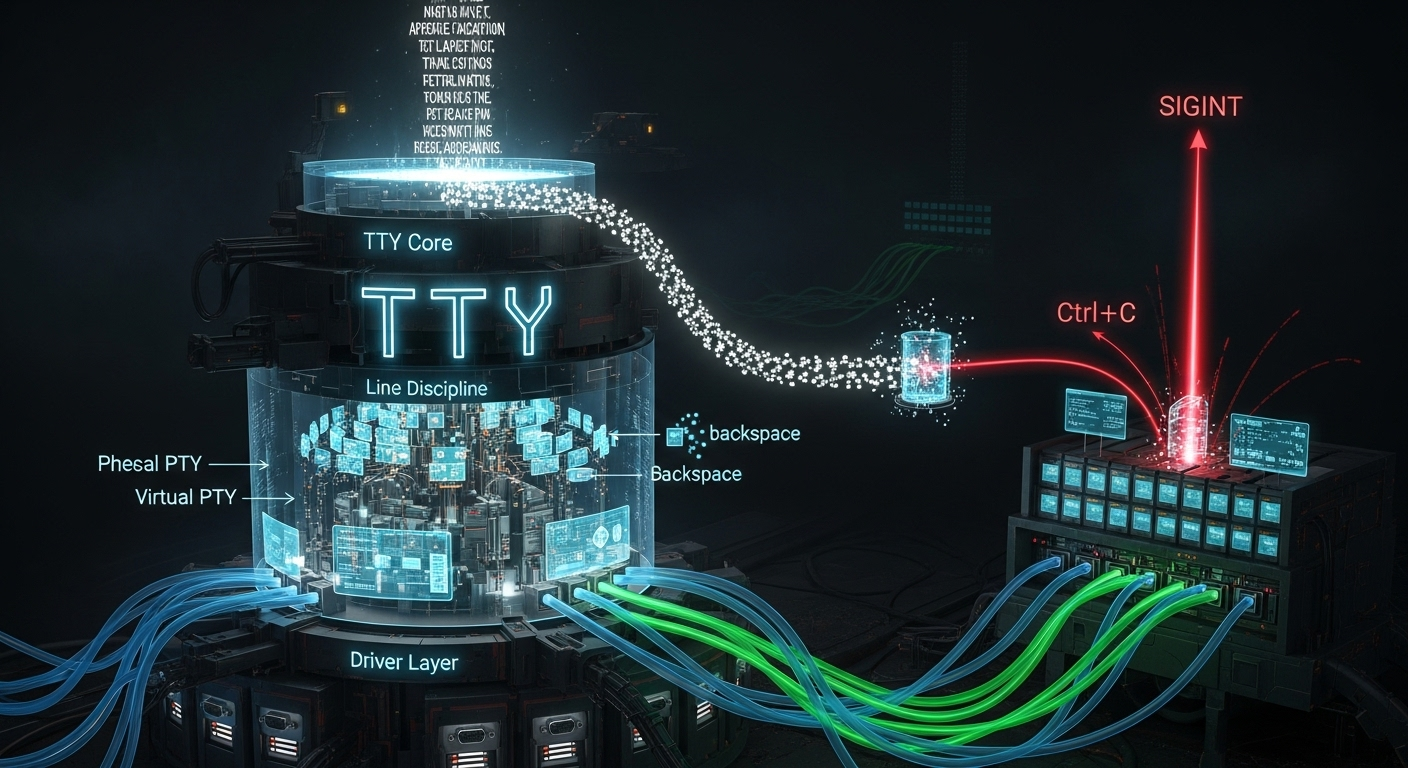
drivers/tty TTY子系统(TTY Subsystem) Linux终端和串口的核心框架
历史与背景
这项技术是为了解决什么特定问题而诞生的?
TTY子系统是Linux/Unix系统中历史最悠久、最核心的子系统之一。它的诞生是为了解决一个根本性的问题:如何为用户进程与各种文本输入/输出设备(即“终端”)之间提供一个统一、抽象的交互接口。
它主要解决了以下几个核心问题:
- 硬件的抽象:早期的计算机通过物理的电传打字机(Teletypewriter, TTY)进行交互。后来出现了各种串行终端(Serial Terminal)。TTY子系统将这些五花八门的硬件抽象成一个标准的字符设备,使得用户进程可以用同样的方式(
read,write)与它们交互。 - 输入处理与行编辑:用户在终端上输入时,难免会打错字。TTY子系统引入了“线路规程”(Line Discipline)的概念,提供了一套通用的输入处理逻辑,包括行缓冲、退格(Backspace)删除、擦除整行(Ctrl+U)等编辑功能。这使得应用程序(如Shell)无需自己实现这些复杂的编辑逻辑。
- 会话管理与信号:TTY子系统是Unix进程和作业控制(Job Control)的基石。它负责解释特殊的控制字符,例如将
Ctrl+C转换为SIGINT信号发送给前台进程组,将Ctrl+Z转换为SIGTSTP信号来挂起进程。 - 支持虚拟终端:随着图形界面和网络的发展,物理终端逐渐被淘汰。TTY子系统演进出了**伪终端(Pseudo Terminal, PTY)**的概念,它在软件中模拟了一个物理终端,使得像
xterm这样的终端模拟器、ssh这样的远程登录会话,以及容器(Docker)都能与Shell等命令行程序进行无缝交互。
它的发展经历了哪些重要的里程碑或版本迭代?
- 源于Unix:TTY子系统的核心设计思想直接继承自最初的Unix系统,专为物理电传打字机和串行终端设计。
- 伪终端(PTY)的引入:这是一个决定性的里程碑。为了支持远程登录(telnet, rlogin, ssh)和图形界面的终端模拟器,PTY被发明出来。它由一对主从设备(Master/Slave)组成,应用程序(如
ssh服务器)通过主设备端(PTM)写入和读取,而Shell等客户端进程则在从设备端(PTS)上运行,认为自己正与一个真实的终端交互。 - Unix 98 PTY模型:早期的BSD PTY模型需要大量预先创建的设备文件(
/dev/ptyXX),管理不便且数量有限。Unix 98 PTY模型引入了/dev/ptmx这个“伪终端复用器”,每次打开它都会动态地创建一个新的主从设备对,对应的从设备出现在/dev/pts/目录下。这成为了现代Linux系统的标准。 - 与Serial驱动的整合:内核中的所有串口(Serial Port)驱动都被设计为TTY驱动的一种,它们负责与硬件(如8250 UART芯片)通信,并将数据流接入TTY核心。
目前该技术的社区活跃度和主流应用情况如何?
TTY子系统是任何Linux/Unix-like系统的基石,其稳定性和重要性无与伦-比。它不是一个经常添加新功能的领域,但其复杂性和历史遗留问题使其成为一个需要持续精细维护的核心部分。
- 主流应用:
- 所有命令行交互:你在任何终端中输入的每一个命令,都在通过一个TTY(通常是PTY)设备。
- 远程服务器管理:每一次SSH登录都会创建一个PTY会话。
- 容器化:
docker exec -it等命令通过创建一个PTY来为容器内的进程提供一个交互式终端。 - 嵌入式与物联网:通过串口与微控制器、调试接口、工业设备等进行通信。
核心原理与设计
它的核心工作原理是什么?
TTY子系统是一个经典的三层架构模型,位于用户空间应用程序和物理/虚拟硬件之间。
- 上层:TTY核心 (
tty_core.c)- 这是整个子系统的中央枢纽。它向用户空间提供了标准的字符设备接口(
/dev/tty*,/dev/pts/*等)和对应的文件操作(open,read,write,ioctl)。 - 它管理着核心数据结构
struct tty_struct,这个结构代表一个打开的终端连接,并将下面两层连接在一起。
- 这是整个子系统的中央枢纽。它向用户空间提供了标准的字符设备接口(
- 中层:线路规程(Line Discipline,
n_tty.c)- 这是TTY子系统的“大脑”。它是一个数据处理层,所有流经TTY的数据都会经过它的处理。
- 输入路径(硬件 -> 进程):当用户在键盘上敲击字符时,数据从底层驱动上来,线路规程负责:
- 回显(Echo):将用户输入的字符再发送回终端显示出来。
- 行缓冲(Canonical Mode):将字符暂存起来,直到用户按下回车键,才将一整行数据提交给上层等待
read()的进程。 - 编辑:处理退格、删除字符等编辑操作。
- 特殊字符解释:捕获
Ctrl+C,Ctrl+Z等特殊字符,并将其转换成发送给进程的信号。
- 输出路径(进程 -> 硬件):当进程
write()数据时,线路规程负责输出处理,例如,它可能会根据设置(ONLCR标志)自动将换行符\n转换为回车+换行\r\n。
- 下层:TTY驱动 (
serial/,vt/,pty.c)- 这是TTY子系统的“手脚”,直接与硬件或虚拟设备打交道。
- 它实现了一组
struct tty_operations回调函数,如.write()(将字符发送到硬件)、.open()(初始化硬件)等。 - 它负责从硬件接收字符,然后调用
tty_flip_buffer_push()等函数将数据“喂”给线路规程进行处理。 - 常见的TTY驱动类型包括:串口驱动、虚拟终端驱动(VT)和伪终端驱动(PTY)。
它的主要优势体现在哪些方面?
- 高度标准化:为所有形式的终端交互提供了单一、一致的编程接口。
- 功能强大:内置了丰富的行编辑、会话管理和信号处理功能。
- 彻底解耦:将应用程序与具体的终端硬件或实现完全分离开来。
它存在哪些已知的劣势、局限性或在特定场景下的不适用性?
- 历史包袱与复杂性:TTY子系统是内核中最古老、最复杂的子系统之一,其代码和大量的
ioctl选项充满了历史痕迹,学习和调试的门槛较高。 - 性能开销:线路规程的逐字符处理引入了不可避免的性能开销。对于需要通过串口进行高速、大块原始数据传输的场景(例如,传输固件文件),TTY的终端语义处理会成为不必要的负担。在这种情况下,通常会将线路规程设置为“原始模式”(raw mode)以最小化开销。
使用场景
在哪些具体的业务或技术场景下,它是首选解决方案?
TTY子系统是任何需要模拟传统终端交互的场景下的唯一且标准的解决方案。
- 交互式Shell:所有命令行Shell(
bash,zsh等)都运行在一个TTY设备上。 - 串口通信:使用
minicom,screen等工具通过串口(如USB-to-Serial适配器)与外部设备(如Arduino, 路由器控制台)通信。 - 文本编辑器:
vim,emacs,nano等在终端中运行的编辑器,完全依赖TTY接口进行屏幕渲染和按键输入。 - 远程登录:
ssh服务器为每个登录会话创建一个PTY,将网络套接字的数据流与远端的Shell进行桥接。
是否有不推荐使用该技术的场景?为什么?
- 进程间通信(IPC):不推荐。如果只是为了在两个进程间交换数据,应该使用更简单高效的管道(Pipe)或套接字(Socket)。PTY是重量级的,专门用于模拟终端,用在这里是大材小用。
- 网络通信:不推荐。进程间的网络通信应使用网络套接字(Network Socket)。
- 高速原始数据流:如上所述,如果一个串行设备只是用来传输二进制数据流,而不需要任何终端编辑或控制字符功能,那么虽然仍需通过TTY设备访问,但也应该立即将其设置为原始模式,以避免不必要的性能损失。
对比分析
请将其 与 其他相似技术 进行详细对比。
| 特性 | TTY Subsystem | Raw Character Device | Pipes / Sockets |
|---|---|---|---|
| 核心功能 | 提供面向终端的、经过处理的双向字节流,附带会话管理。 | 提供未经处理的、原始的双向字节流。 | 提供通用的、面向连接或数据报的双向通信通道。 |
| 数据模型 | 面向行(在规范模式下),有编辑、回显、信号等语义。 | 面向字节,所读即所写,无任何中间处理。 | 面向字节流(TCP)或数据包(UDP),是通用的数据传输机制。 |
| 典型设备 | /dev/ttyS0 (串口), /dev/pts/5 (伪终端)。 |
/dev/urandom, 某些专用硬件的驱动接口。 |
N/A (通过系统调用创建,不在/dev下)。 |
| 主要用途 | 人机交互,模拟终端会话。 | 与硬件直接交互,传输原始数据。 | 进程间/机器间通信 (IPC/Network)。 |
| 复杂性 | 非常高。包含复杂的线路规程和ioctl状态机。 |
低。通常只有简单的read/write操作。 |
中等。API丰富,但概念比TTY清晰。 |
| 适用场景 | 任何需要让程序认为它在和“人”通过终端交互的场景。 | 驱动程序需要一个简单的、无加工的字节流接口给用户空间。 | 任何形式的程序间数据交换。 |
与其他子系统的差异
与
console的区别:console是系统的默认输出设备,用于显示内核日志和启动信息。tty是更广义的终端设备管理子系统,console只是其中的一部分。
与
serial的区别:serial子系统专注于串口设备的管理,而tty子系统管理所有类型的终端设备,包括串口。
与
pts的区别:pts是伪终端设备的实现,属于tty子系统的一部分,专门用于虚拟终端。
总结
tty 是 Linux 内核中用于管理终端设备的核心子系统,涵盖了物理终端、串口终端和伪终端等多种设备类型。它在用户与系统交互、调试和远程登录等场景中扮演着重要角色。尽管其历史可以追溯到早期的电传打字机,但在现代计算中,tty 的概念已经被扩展和抽象,成为操作系统中不可或缺的一部分。
include/linux/console.h
console_is_registered 检查控制台是否已注册
1 | //检查con->node是否未哈希 |
drivers/tty/n_tty.c
n_tty_ops
1 | static struct tty_ldisc_ops n_tty_ops = { |
n_tty_init
1 | void __init n_tty_init(void) |
drivers/tty/n_null.c TTY 空线路规程
本代码片段展示了一个极其简单但概念上很重要的 TTY(电传打字机)子系统组件:空线路规程(n_null)。其核心功能是提供一个“黑洞”式的线路规程,它不执行任何实际的 I/O 操作,对于任何读或写请求,它都直接返回错误。它的主要用途是在 TTY 设备的初始化或关闭过程中的“失败路径”上,作为一个安全的、无操作的占位符,防止系统在这些过渡状态下出现未定义的行为。
实现原理分析
此代码是 TTY 线路规程插件模型的一个最简实现。
TTY 线路规程(Line Discipline)的角色:
- 在 Linux TTY 架构中,线路规程位于 TTY 核心和底层 TTY 驱动(如串口驱动)之间。它负责实现特定于会话的协议和编辑功能。
- 最常见的线路规程是
N_TTY,它实现了标准的终端行为(行编辑、回显、特殊字符处理等)。其他规程还包括用于 PPP、SLIP 等协议的N_PPP,N_SLIP。 - 内核允许动态地为一个 TTY 设备切换不同的线路规程。
n_null的极简实现:- I/O 操作:
n_null_read和n_null_write是这个规程的核心。它们不做任何事情,直接返回-EOPNOTSUPP(不支持该操作)。这意味着任何尝试通过一个设置了n_null规程的 TTY 文件描述符进行读写的用户空间程序,都会立即失败。 tty_ldisc_ops结构:null_ldisc结构将这些无操作的函数与线路规程的元数据(名称"n_null"和编号N_NULL)绑定在一起,形成一个完整的线路规程“插件”。
- I/O 操作:
模块化注册:
n_null_init函数在模块加载时被调用,它通过tty_register_ldisc将null_ldisc注册到 TTY 核心的全局线路规程列表中。BUG_ON确保了如果注册失败(这在正常情况下几乎不可能发生),内核会立即崩溃,表明存在严重的初始化问题。n_null_exit函数则对称地调用tty_unregister_ldisc来注销它。
代码分析
1 | // SPDX-License-Identifier: GPL-2.0 |
drivers/tty/tty_ldisc.c
tty_register_ldisc - 内核注册新的行规程(line discipline)
1 | /** |
drivers/tty/tty_io.c
tty_class_init: 注册TTY设备类
此代码片段的核心作用是在Linux内核中注册一个名为 “tty” 的设备类 (struct class)。这个类是所有终端设备 (TTY devices) 的容器, 包括物理串口、虚拟控制台和伪终端等。注册这个类是内核TTY子系统初始化的基础步骤, 它使得后续的TTY驱动程序能将自己创建的设备归入这个统一的分类下, 并最终在sysfs中表现为/sys/class/tty/目录。
1 | /* |
tty_register_device_attr: TTY设备注册的核心
本代码片段展示了Linux TTY子系统的核心功能之一:tty_register_device_attr函数。这是将一个抽象的TTY线路(由tty_driver和index定义)实例化为一个具体的、在内核设备模型中可见的struct device的最终实现。其核心功能是动态分配一个struct device,为其赋予设备号(dev_t)、名称、类别(class)和sysfs属性,然后将其注册到设备模型中,并最终通过cdev(字符设备)接口,在/dev目录下创建用户可见的设备文件。
实现原理分析
此函数是连接三个主要内核子系统的枢纽:TTY子系统、设备模型和虚拟文件系统(VFS)。
动态设备创建:
- 与静态分配设备号的旧驱动模型不同,此函数是为
TTY_DRIVER_DYNAMIC_DEV标志设计的,它允许驱动在运行时(例如,当一个USB串口被插入时)才注册设备。 kzalloc(sizeof(*dev), GFP_KERNEL): 它不是使用一个预先存在的struct device,而是为每一个TTY线路动态地分配一个新的struct device实例。
- 与静态分配设备号的旧驱动模型不同,此函数是为
三大子系统的链接:
- 设备号 (
dev_t):MKDEV(driver->major, driver->minor_start) + index计算出全局唯一的设备号。这个dev_t是内核的“通用语言”,是连接一切的关键。 - 链接到设备模型:
dev->class = &tty_class;: 将新设备归入tty类。这决定了它在sysfs中的位置(/sys/class/tty/)。dev->parent = device;: 设置其父设备,构建出硬件的拓扑结构(例如,一个tty设备是某个USB设备的子节点)。dev_set_name(...): 设置设备名(如ttyS0),这也是它在sysfs中显示的名字。device_register(dev): 将这个配置好的struct device正式注册到内核设备模型中,使其在sysfs中可见。
- 链接到VFS (
tty_cdev_add):- 这是创建字符设备文件的关键一步。
cdev是字符设备的内核抽象。 tty_cdev_add函数会分配一个cdev结构,将其与tty_driver提供的文件操作(file_operations)关联起来,并使用之前计算好的dev_t,将其注册到VFS。- 当这个函数成功执行后,用户空间的
udev守护进程会收到一个KOBJ_ADDuevent事件,并根据dev_t在/dev目录下自动创建对应的设备文件(如/dev/ttyS0)。
- 这是创建字符设备文件的关键一步。
- 设备号 (
同步与生命周期管理:
dev_set_uevent_suppress(dev, 1): 这是一个巧妙的同步技巧。它在设备注册的早期阶段抑制uevent的发送,防止用户空间(如udev)在设备尚未完全初始化(特别是cdev还未添加)时就尝试访问它。kobject_uevent(&dev->kobj, KOBJ_ADD): 在所有步骤都完成后,手动触发一个”ADD” uevent,通知用户空间设备已完全就绪。dev->release = tty_device_create_release: 设置了release回调函数。当这个struct device的最后一个引用被put_device释放时,内核会自动调用此函数来kfree掉kzalloc分配的内存,确保了无内存泄露。
代码分析
1 | /** |
drivers/tty/tty_port.c
tty_port_register_device & ..._serdev: TTY/Serdev 设备的动态注册
本代码片段展示了Linux TTY核心层提供给驱动程序的一系列高级API,用于将一个tty_port(代表硬件端口)注册为一个用户可见的设备。其核心功能是提供一个分层的、多功能的注册接口,最关键的是tty_port_register_device_attr_serdev函数,它能够动态地决定是将一个物理串口注册为一个传统的、供用户空间直接访问的TTY设备(如/dev/ttyS0),还是注册为一个serdev(Serial Device)总线控制器,供内核中的其他驱动(如GPS、Bluetooth驱动)绑定。
实现原理分析
这段代码是TTY子系统高度抽象和模块化的体现。它通过一系列封装函数,为驱动作者提供了不同层次的控制,并优雅地集成了serdev框架。
最底层:
tty_port_link_device:- 职责: 这是最基础的操作,它只做一件事:在
tty_driver的ports数组中,建立一个从线路号(index)到tty_port的指针链接。 - 作用: 它仅仅是告知TTY核心:“嘿,对于线路
X,它的硬件抽象是这个tty_port结构体”。它本身不创建任何设备节点或sysfs条目。 - 使用场景: 内核文档明确指出这是“最后的手段”,只应在无法使用更高级的
register函数时才使用。
- 职责: 这是最基础的操作,它只做一件事:在
标准注册:
tty_port_register_device_attr:- 职责: 这是标准的“端口到设备”的注册函数。
- 实现: 它是一个封装,执行两个步骤:
- 调用
tty_port_link_device来建立逻辑链接。 - 调用
tty_register_device_attr(TTY核心的内部函数),这个函数负责所有繁重的工作:创建struct device实例,在/sys下创建设备目录和属性文件,并通过cdev接口在/dev下创建字符设备文件。
- 调用
serdev集成与动态决策 (tty_port_register_device_attr_serdev):- 职责: 这是功能最强大的注册函数,它实现了TTY和
serdev之间的动态二选一。 serdev是什么?:serdev框架用于管理那些连接到串口上的设备(如GPS模块)。在这种情况下,内核本身需要一个驱动来和GPS模块通信,而不是让用户空间直接读写原始的串口数据。此时,物理串口就扮演了一个“总线控制器”的角色。- 实现逻辑:
- 链接: 首先,它和标准注册一样,调用
tty_port_link_device。 - 尝试
serdev: 然后,它调用serdev_tty_port_register。这个函数会检查设备树,看当前串口节点下是否有子节点。如果有,就意味着有一个设备连接到了这个串口。serdev框架会为这个连接创建一个serdev_device,并将物理串口注册为一个serdev_controller。 - 决策点:
if (PTR_ERR(dev) != -ENODEV)。这是决策的关键。- 如果
serdev_tty_port_register成功,或者返回了除-ENODEV之外的任何错误,函数会直接返回。它不会继续创建TTY设备节点。这意味着端口被serdev框架“接管”了。 - 只有当
serdev_tty_port_register返回-ENODEV(表示“没有找到设备”,即设备树中没有对应的子节点)时,这个if条件才为假。
- 如果
- 回退到TTY: 在
if条件为假的情况下,代码会回退(fallback)到调用tty_register_device_attr,将这个端口注册为一个标准的TTY设备。
- 链接: 首先,它和标准注册一样,调用
- 这个“尝试-回退”的逻辑使得同一个驱动代码可以无缝支持两种不同的用例,而具体行为由设备树来配置。
- 职责: 这是功能最强大的注册函数,它实现了TTY和
注销 (
tty_port_unregister_device):- 它的逻辑与
..._serdev注册函数完美镜像。 - 它首先尝试
serdev_tty_port_unregister。如果成功(返回0),说明它是一个serdev控制器,清理完成,函数返回。 - 如果失败(返回非0),说明它不是
serdev控制器,于是它回退到调用tty_unregister_device来清理标准的TTY设备。
- 它的逻辑与
代码分析
1 | /** |
include/uapi/linux/tty_flags.h
ASYNC_* 标志: 用户空间对串口驱动行为的底层控制
本代码片段是一个UAPI(User API)头文件,它定义了一系列ASYNCB_*(位索引)和ASYNC_*(位掩码)宏。其核心功能是向用户空间应用程序(如setserial、agetty等)提供一个标准的、稳定的API,用于通过ioctl(TIOCSSERIAL)系统调用来精细地控制串口驱动的底层行为。这些标志是struct serial_struct结构体中flags字段的“语言”。这个文件构成了内核UPF_*标志与用户空间之间公开的、有文档记录的契约。
实现原理分析
此文件的核心原理与内核中的标志位定义类似,即位掩码,但它的服务对象是用户空间。
双层宏定义:
ASYNCB_*: 定义了每个标志所对应的比特位索引号(bit number)。例如,ASYNCB_SPD_HI是4。这种定义方式便于使用{test,set,clear}_bit这类位操作函数(虽然这主要在内核中使用,但定义风格保持了一致)。ASYNC_*: 使用位移操作(1U << ASYNCB_*),将位索引号转换为可以直接用于按位与/或操作的位掩码。例如,ASYNC_SPD_HI就是(1U << 4),即0x10。用户空间程序直接使用这些ASYNC_*掩码。
用户空间与内核的契约:
- 这个头文件位于内核源码的
include/uapi目录下,意味着它会被导出并安装到系统的/usr/include/linux目录,供所有用户空间的C程序包含。 - 它定义了一个ABI(Application Binary Interface)。一旦发布,这些宏的值就不应再改变,否则会破坏已编译的用户空间程序的兼容性。
- 如前一个分析所述,内核中的
UPF_*标志被定义为与这些ASYNC_*标志完全等值,从而实现了用户空间设置与内核驱动标志之间的无缝传递。
- 这个头文件位于内核源码的
标志的演进与废弃:
- 注释中包含了非常重要的历史信息。许多标志后面都带有
[x],表示**“已废弃”(defunct)**。例如ASYNCB_SPLIT_TERMIOS。这说明serial_struct接口是一个历史悠久的、有些陈旧的API,它的一些功能已经被更现代的termios接口所取代。 #ifndef __KERNEL__: 这个预处理器块中的宏只对用户空间可见。它们定义了一些内核曾经使用但现在已废弃、且从未真正暴露给用户的内部标志。这是一种向后兼容和信息隐藏的手段。
- 注释中包含了非常重要的历史信息。许多标志后面都带有
代码分析
1 | /* SPDX-License-Identifier: GPL-2.0 WITH Linux-syscall-note */ |
drivers/tty/tty_baudrate.c
tty_termios_baud_rate & tty_termios_encode_baud_rate: termios 波特率的编解码器
本代码片段展示了Linux TTY核心层用于转换termios波特率的两个核心辅助函数。它们是termios接口与驱动程序可理解的数值波特率之间的双向编解码器。
- 解码 (
tty_termios_baud_rate): 将termios->c_cflag中编码的Bxxxx符号,翻译成一个具体的数值波特率(如115200)。 - 编码 (
tty_termios_encode_baud_rate): 将一个具体的数值波特率,反向编码成termios->c_cflag中的**Bxxxx符号**,如果找不到精确匹配,则使用特殊的BOTHER标志。
这两个函数是连接抽象的POSIX termios接口与底层驱动所需具体数值的桥梁。
实现原理分析
此机制的核心是查表法和对**特殊标志BOTHER**的巧妙运用。
波特率表 (
baud_table&baud_bits):- 内核维护着两个严格同步的静态数组:
baud_table: 存储了所有标准波特率的数值(speed_t类型,即unsigned int)。baud_bits: 存储了与baud_table中每个数值相对应的**Bxxxx符号**(tcflag_t类型,来自termbits.h)。
- 例如,
baud_table[13]是9600,而baud_bits[13]是B9600。这两个表的索引是相同的。
- 内核维护着两个严格同步的静态数组:
解码过程 (
tty_termios_baud_rate):- 职责:
Bxxxx符号 ->speed_t数值。 - 实现:
cbaud = termios->c_cflag & CBAUD;: 首先,它从c_cflag中屏蔽出与波特率相关的比特位(CBAUD掩码)。Bxxxx符号本质上就是一些小整数(0-15)。BOTHER处理: 如果cbaud等于BOTHER(一个特殊的标志,表示“其他速率”),这意味着用户想要一个非标准的、任意的波特率。在这种情况下,函数会直接返回存储在termios->c_ospeed字段中的具体数值。CBAUDEX处理:CBAUDEX是用于更高波特率的扩展标志。如果它被设置,cbaud的值需要加上一个偏移量(15)才能得到正确的表索引。- 查表: 最终,它使用计算出的
cbaud作为索引,在baud_table中查找并返回对应的数值。例如,如果cbaud是13,它就返回baud_table[13],即9600。
- 职责:
编码过程 (
tty_termios_encode_baud_rate):- 职责:
speed_t数值 ->Bxxxx符号。 - 实现: 这是一个更复杂的过程,因为它需要处理近似匹配。
- 保存数值:
termios->c_ispeed = ibaud; termios->c_ospeed = obaud;首先,它总是将用户请求的精确数值波特率保存在c_ispeed和c_ospeed字段中。 - 模糊搜索: 它遍历整个
baud_table。对于每个标准速率,它会检查用户请求的速率(ibaud/obaud)是否落在一个很小的误差范围内 (obaud - oclose <= baud_table[i] && obaud + oclose >= baud_table[i])。 - 优先标准符号: 如果找到了一个足够接近的标准速率,它就会将对应的
Bxxxx符号(来自baud_bits)设置到termios->c_cflag中。这是为了向后兼容,因为许多老的应用程序只认识标准的Bxxxx符号。 - 回退到
BOTHER: 如果在整个表中都没有找到近似的匹配项,函数就会在termios->c_cflag中设置BOTHER标志。
- 保存数值:
- 作用: 这个函数的主要调用者是底层驱动程序。当驱动程序发现自己无法精确实现用户请求的波特率,但可以实现一个非常接近的速率时,它会调用这个函数来更新
termios结构,以便通过tcgetattr()系统调用将实际使用的速率(包括其对应的Bxxxx符号)报告回用户空间。
- 职责:
代码分析
1 | /* |
drivers/tty/tty_buffer.c
tty_buffer_request_room & __tty_insert_flip_string_flags: TTY Flip Buffer的写入核心
本代码片段展示了Linux TTY子系统输入缓冲的核心机制——flip_buffer的写入实现。__tty_buffer_request_room是缓冲区的空间管理器,负责在需要时动态地分配新的内存块。__tty_insert_flip_string_flags则是数据写入器,它使用空间管理器来确保有足够的空间,然后将字符数据和与之对应的标志(如TTY_NORMAL, TTY_PARITY)拷贝到缓冲区中。这些函数是连接底层硬件驱动(如uart_insert_char的调用者)与上层线路规程(line discipline)的数据中转站。
实现原理分析
此机制的核心是一个生产者-消费者模型,它使用一个链表式的、分块的缓冲区,并通过内存屏障来实现高效的、近乎无锁的同步。
Flip Buffer 数据结构:
tty_port->buf(struct tty_bufhead): 这是缓冲区的“头部”,包含了指向链表头(head)和尾(tail)的指针。tty_buffer: 这是缓冲区的基本内存块,通常大小为一个页面(TTY_BUFFER_PAGE)。它包含一个字符缓冲区和一个可选的标志缓冲区。flags成员表示该缓冲区是否包含标志。- 生产者: 底层驱动(如
stm32_usart_receive_chars_pio)是生产者,负责向缓冲区写入数据。它总是操作buf->tail指向的缓冲区。 - 消费者: TTY核心的后台工作(
tty_port_default_work)是消费者,负责从缓冲区读取数据并递交给线路规程。它总是操作buf->head指向的缓冲区。
空间管理 (
__tty_buffer_request_room):- 职责: 确保
tail缓冲区中至少有size大小的可用空间。 - 快速路径:
if (!change && left >= size)。如果当前tail缓冲区有足够的剩余空间,并且不需要从“无标志”模式切换到“有标志”模式,则函数直接返回,开销极小。 - 慢速路径 (分配):
tty_buffer_alloc(port, size): 当空间不足时,调用此函数从一个预分配的缓冲池(port->buf.free)中获取一个新的tty_buffer,或者如果池为空,则动态分配一个新的页面。- 链表链接: 新分配的缓冲区
n成为新的tail。旧的tail缓冲区的next指针被原子地设置为指向n。
- 同步与内存屏障:
smp_store_release(&b->commit, b->used): 这是关键的同步点。smp_store_release是一个带有“释放”语义的原子写操作。它有两个作用:- 将旧缓冲区
b的commit计数更新为其实际使用的大小used。 - 发布(publish)所有在此操作之前对缓冲区数据(字符和标志)的写入。它确保了消费者在看到更新的
commit值时,也一定能看到所有的数据。
- 将旧缓冲区
smp_store_release(&b->next, n): 同样,它原子地更新next指针,并发布这个更新。这确保了消费者在处理完一个缓冲区后,能够安全地看到链表中的下一个缓冲区。
- 职责: 确保
数据写入 (
__tty_insert_flip_string_flags):- 职责: 将一个字符串及其标志高效地拷贝到
flip_buffer中。 - 分块拷贝:
do { ... } while (unlikely(size > copied))。这个循环处理了需要跨越多个tty_buffer块的大数据写入。 - 循环体:
goal = min_t(...): 计算本次循环要拷贝的数据量,最大不超过一个缓冲区的大小。__tty_buffer_request_room(port, goal, ...): 为本次拷贝请求空间。memcpy(...): 将字符数据和标志数据分别拷贝到char_buf_ptr和flag_buf_ptr指向的位置。tb->used += space;: 更新tail缓冲区的已用空间计数。
- 职责: 将一个字符串及其标志高效地拷贝到
代码分析
1 | /** |
tty_buffer_alloc & tty_buffer_free: TTY Flip Buffer的内存池管理
本代码片段展示了Linux TTY flip_buffer机制的内存管理后台。其核心功能是通过tty_buffer_alloc和tty_buffer_free这一对函数,实现对tty_buffer内存块的高效分配与回收。这个机制采用了一种混合策略:它维护一个小的、无锁的空闲链表(free list),用于快速重用小尺寸的缓冲区,同时在需要更大尺寸或空闲链表为空时,回退到标准的内核内存分配器(kmalloc)。tty_buffer_free_all则是用于在设备关闭时彻底清理所有缓冲区的最终清理函数。
实现原理分析
此机制的设计目标是在保证高性能(特别是在中断上下文中)和内存效率之间取得平衡。
混合分配策略 (
tty_buffer_alloc):- 职责: 分配一个新的、大小至少为
size的tty_buffer。 - 尺寸对齐:
size = __ALIGN_MASK(size, TTYB_ALIGN_MASK);它首先将请求的尺寸向上对齐到一个合适的边界(通常是256字节的倍数),以减少内存碎片并标准化缓冲区大小。 - 快速路径 (从空闲链表获取):
if (size <= MIN_TTYB_SIZE): 只有当请求的尺寸是小尺寸时,它才会尝试从空闲链表中获取。free = llist_del_first(&port->buf.free);: 这是关键。llist是一个无锁单向链表,专为单生产者/单消费者场景设计,但在这里用于多生产者(多个中断)/单消费者(清理函数)场景,llist_del_first是一个原子操作,可以安全地从链表头部移除一个节点,无需任何锁。- 优点: 从空闲链表获取缓冲区的速度极快,因为它不涉及调用重量级的
kmalloc,并且是无锁的,非常适合在中断上下文中使用。
- 慢速路径 (从
kmalloc分配):- 当请求的是大尺寸缓冲区,或者空闲链表为空时,代码会回退到调用
kmalloc。 atomic_read(&port->buf.mem_used) > port->buf.mem_limit: 这是一个内存限额检查,防止单个TTY设备消耗过多的内核内存。GFP_ATOMIC | __GFP_NOWARN: 使用GFP_ATOMIC标志进行分配,这意味着它是一个高性能、不可睡眠的分配请求,适合在中断上下文中使用。
- 当请求的是大尺寸缓冲区,或者空闲链表为空时,代码会回退到调用
- 初始化: 无论从哪里获得缓冲区,
tty_buffer_reset都会被调用,将其所有成员(used,commit,next等)重置为初始状态。
- 职责: 分配一个新的、大小至少为
回收策略 (
tty_buffer_free):- 职责: 回收一个不再使用的
tty_buffer。 - 策略:
if (b->size > MIN_TTYB_SIZE): 如果缓冲区是大尺寸的,则直接调用kfree将其彻底释放回系统。else if (b->size > 0): 如果是小尺寸的,则调用llist_add(&b->free, &buf->free)将其放回空闲链表的头部,以备下次快速分配。
- 这个简单的策略旨在平衡内存占用和分配性能:频繁使用的小缓冲区被缓存起来,而不常用的大缓冲区则及时释放,避免占用过多内存。
- 职责: 回收一个不再使用的
最终清理 (
tty_buffer_free_all):- 职责: 在TTY端口被销毁时,释放所有与之关联的缓冲区,包括正在使用的数据链表和空闲链表。
- 实现:
- 遍历
buf->head链表,逐个kfree掉所有包含数据的缓冲区。 llist_del_all(&buf->free): 原子地将整个空闲链表取下。- 遍历这个取下的链表,逐个
kfree掉所有空闲的缓冲区。 WARN(...): 最后,它会检查内存使用量的原子计数器mem_used是否归零,这是一个健全性检查,用于在调试时发现内存泄露。
- 遍历
代码分析
1 | /** |
flush_to_ldisc & tty_flip_buffer_push: TTY Flip Buffer的数据消费与调度
本代码片段展示了Linux TTY flip_buffer机制的后半部分——即消费者(Consumer)的实现。其核心功能是通过flush_to_ldisc这个工作队列(workqueue)处理函数,从flip_buffer中读取由驱动程序(生产者)放入的数据,并将其递交给上层的线路规程(line discipline)进行处理(如行编辑、信号生成等)。tty_flip_buffer_push则是生产者用来触发这个消费过程的API。
实现原理分析
此机制是flip_buffer生产者-消费者模型的核心调度逻辑,它通过工作队列实现了从硬中断上下文到进程上下文的异步工作转移,并通过内存屏障确保了数据的安全传递。
消费者 (
flush_to_ldisc):- 职责: 作为
flip_buffer的唯一消费者,负责读取数据并将其“冲刷”(flush)到线路规程。 - 上下文: 它是一个
work_struct的处理函数,这意味着它总是在一个内核线程(进程上下文)中执行。这非常重要,因为它允许在处理数据时安全地睡眠(例如,如果线路规程需要等待锁)。 - 单线程保证:
mutex_lock(&buf->lock)确保了在任何时刻,只有一个CPU核心上的一个线程在执行flush_to_ldisc的逻辑,即消费者是单线程的,这极大地简化了缓冲区的读取逻辑。 - 读取循环 (
while (1)):- 获取数据量:
count = smp_load_acquire(&head->commit) - head->read;这是关键的同步点。smp_load_acquire是一个带有“获取”语义的原子读操作。它确保在读取commit计数的同时,也“获取”了生产者通过smp_store_release发布的所有数据。commit是生产者写入的数据量,read是消费者已读取的数据量,差值就是新数据的量。 - 空缓冲区处理: 如果
count为0,表示当前head缓冲区的数据已被处理完毕。代码会尝试将buf->head指针移动到链表中的下一个缓冲区,并释放掉旧的head。 - 递交线路规程:
rcvd = receive_buf(port, head, count);这是数据递交的核心。receive_buf(代码未显示,通常指向tty_ldisc_receive_buf)会调用当前TTY线路规程的.receive_buf方法,将数据块和标志块的指针以及count传递给它。 head->read += rcvd;: 更新已读计数。cond_resched(): 在处理完一个数据块后,主动调用调度器,检查是否有更高优先级的任务需要运行。这防止了在处理大量数据时,flush_to_ldisc长时间独占CPU,保证了系统的响应性。
- 获取数据量:
- 职责: 作为
生产者触发器 (
tty_flip_buffer_push):- 职责: 由生产者(如串口驱动的ISR或DMA完成回调)调用,用于通知消费者“有新数据了,请来处理”。
- 实现: 这是一个两步过程。
tty_flip_buffer_commit(buf->tail): 发布数据。它调用smp_store_release(&tail->commit, tail->used),原子地更新tail缓冲区的commit计数。这个release操作与flush_to_ldisc中的acquire操作配对,构成了一个内存屏障,确保了数据在被消费者看到之前,已经完全写入内存。queue_work(system_unbound_wq, &buf->work): 调度消费者。它将buf->work(在tty_buffer_init中被初始化为指向flush_to_ldisc)提交到系统的工作队列中。内核的工作队列子系统会在稍后的某个时间点,在一个内核线程中执行flush_to_ldisc函数。
初始化 (
tty_buffer_init):- 它负责建立整个
flip_buffer的初始状态,包括:- 初始化互斥锁和无锁空闲链表。
- 创建一个“哨兵”(sentinel)节点,使得
head和tail指针永远不会为NULL,简化了链表操作。 INIT_WORK(&buf->work, flush_to_ldisc): 将buf->work与flush_to_ldisc函数绑定,为后续的queue_work调用做好准备。
- 它负责建立整个
代码分析
1 | static size_t |
 微信
微信- 支付寶







