[toc]
mm/vmscan.c 页面回收(Page Reclaim) 内核内存管理的核心压力调节器
历史与背景
这项技术是为了解决什么特定问题而诞生的?
mm/vmscan.c 中的代码是为了解决计算机科学中最基本的问题之一:物理内存是一种有限资源。当系统运行的应用程序和内核本身需要的内存总量超过了可用的物理RAM时,操作系统必须有一种机制来释放一些当前已分配但“不那么重要”的内存,以便为新的、更紧迫的内存请求腾出空间。
如果没有页面回收机制,系统在内存耗尽时唯一的选择就是拒绝新的内存分配请求,这将导致应用程序崩溃或系统完全停止响应。vmscan.c 实现的页面回收(Page Reclaim)算法,其核心目标是在内存压力(Memory Pressure)下,智能地选择并回收内存页面,从而保证系统的持续运行和响应能力。
它的发展经历了哪些重要的里程碑或版本迭代?
Linux的页面回收算法经历了重大的演进,以适应不断变化的硬件和工作负载:
- 早期的LRU:最初的Linux内核使用了相当简单的“最近最少使用”(Least Recently Used, LRU)算法。
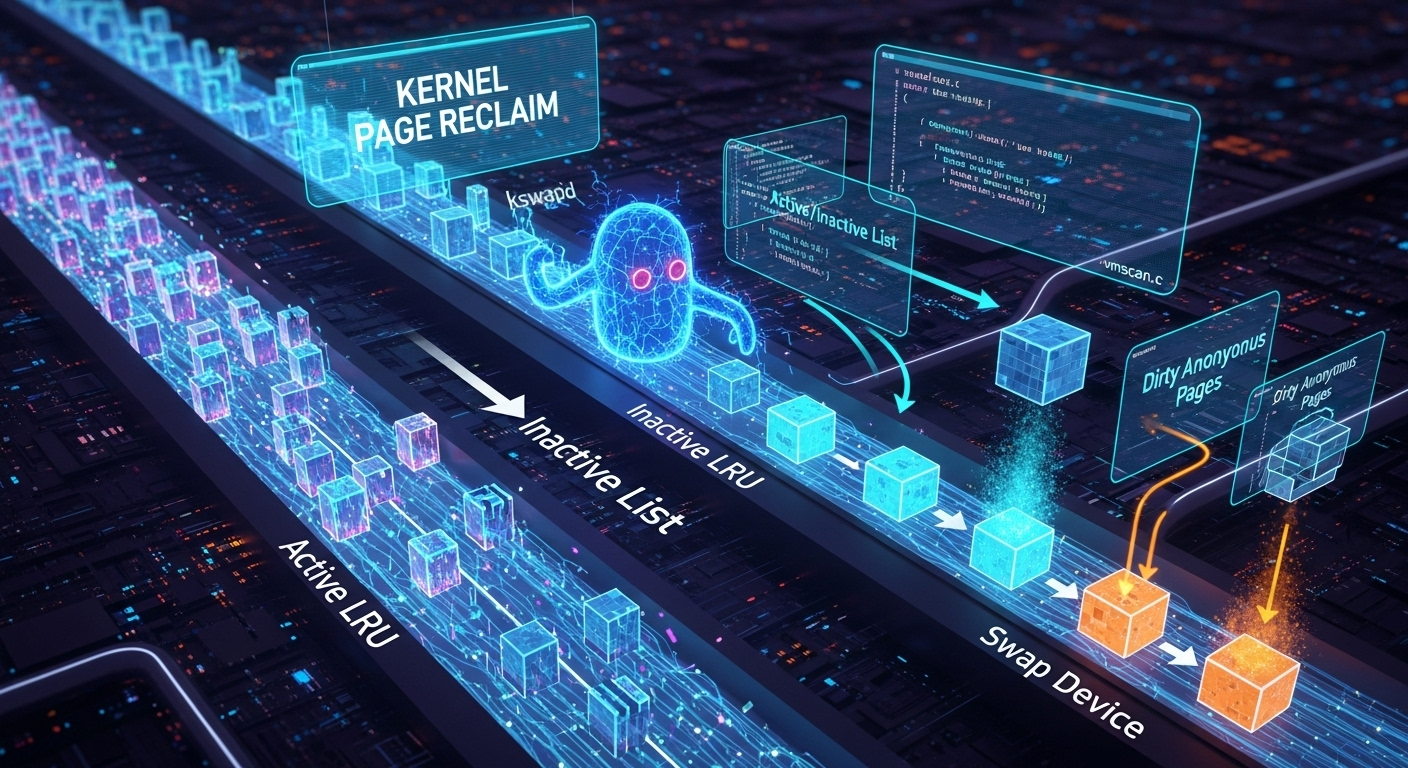
- 两阶段LRU (Active/Inactive Lists):一个革命性的改进是引入了Active和Inactive两个链表来管理页面。由Rik van Riel等人提出的这个方案,旨在更好地区分真正“热”的(经常被访问)页面和“冷”的(不常被访问)页面,从而避免了“缓存污染”(当一次大的、顺序的读操作将所有热数据都冲出缓存时)的问题,极大地提高了回收决策的准确性。
vmscan.c的核心逻辑就是围绕这个模型构建的。 - File vs. Anonymous Pages分离:内核进一步将LRU链表区分为文件页面(File Pages)和匿名页面(Anonymous Pages)。这两类页面的回收成本截然不同:干净的文件页面可以直接丢弃(需要时可从磁盘重新读取),而匿名的“脏”页面则必须先写入交换空间(swap),这是一个昂贵的操作。这种分离使得回收策略可以更加精细。
- NUMA感知:在非统一内存访问(NUMA)架构的服务器上,
vmscan.c发展为NUMA感知的。这意味着内核会优先在内存压力所在的NUMA节点上进行本地回收,以避免昂贵的跨节点内存访问。 - 多代LRU (MGLRU):近年来,为了解决传统两阶段LRU在某些现代工作负载下的不足,Google的工程师们提出了多代LRU(Multi-Generational LRU)机制。MGLRU通过更精细的页面老化和分代管理,旨在做出更优的回收决策,目前已合并到主线内核中,作为一种可选的、更现代化的回收策略。
目前该技术的社区活跃度和主流应用情况如何?
页面回收是Linux内存管理子系统的心脏,其稳定性和效率直接决定了整个操作系统的性能表现。因此,它一直是内核社区中研究、讨论和优化的热点。它被应用于所有运行Linux的设备上,从最小的嵌入式系统到最大的超级计算机。任何时候,只要Linux系统遇到内存压力,vmscan.c 中的代码就会被激活。
核心原理与设计
它的核心工作原理是什么?
mm/vmscan.c 的核心工作是扫描和回收页面,其逻辑由两个主要场景触发:
- kswapd(后台回收):这是一个内核线程,每个NUMA节点都有一个。它在后台被周期性地唤醒,检查当前节点的内存水位。如果空闲内存低于某个“低水位线”(low watermark),
kswapd就会被唤醒并开始异步地、主动地回收页面,直到空闲内存恢复到“高水位线”(high watermark)。这是一种预防性的机制。 - 直接回收(Direct Reclaim):当一个进程请求分配内存,但系统空闲内存已经低于“最低水位线”(min watermark)时,意味着
kswapd已经跟不上内存消耗的速度。此时,该进程会被阻塞,并同步地、被动地调用页面回收代码为自己腾出空间。这是一个高成本的操作,因为它会增加应用程序的延迟。
回收过程的核心步骤:
- 扫描LRU链表:回收算法主要扫描上文提到的四个LRU链表:
active_file,inactive_file,active_anon,inactive_anon。 - 页面老化(Aging):算法从
active链表的尾部开始扫描。当它检查一个页面时,会查看该页面是否被访问过(通过CPU的Accessed bit)。- 如果页面被访问过,则认为它“还很热”,会清除其访问标记,并将其留在
active链表中,但可能会移到链表头部,给它一次新的机会。 - 如果页面未被访问过,则认为它“变冷了”,会将其从
active链表移动到inactive链表的头部。
- 如果页面被访问过,则认为它“还很热”,会清除其访问标记,并将其留在
- 选择回收候选者:算法从
inactive链表的尾部开始扫描,这里的页面是“最冷”的。- 如果一个
inactive页面再次被访问,它会被“激活”,重新移回到active链表。 - 如果一个
inactive页面长时间未被访问,它就成为回收的候选者。
- 如果一个
- 执行回收:
- 干净的文件页面:直接从页缓存中移除,释放内存。这是成本最低的回收方式。
- 脏的文件页面:必须先将其内容写回到磁盘(writeback),这是一个I/O操作。写回完成后,页面才能被释放。
- 脏的匿名页面:必须将其内容写入到交换空间(swap out),这也是一个昂贵的I/O操作。
- slab缓存:
vmscan.c也会调用shrink_slab()来尝试收缩内核的slab/slub分配器缓存(如dentry, inode缓存)。
它的主要优势体现在哪些方面?
- 系统稳定性:它是Linux系统在高内存压力下仍能保持运行的关键。
- 性能启发式:两阶段LRU模型在大多数通用工作负载下,都能很好地平衡性能和内存使用,有效区分工作集(working set)和可回收内存。
- 区分处理:通过分离文件页和匿名页,系统可以优先回收成本较低的页面。
vm.swappiness这个sysctl参数就是用来调节回收文件页和匿名页的倾向性的。
它存在哪些已知的劣势、局限性或在特定场景下的不适用性?
- 性能抖动:直接回收会给应用程序带来显著的延迟,是性能优化的重点关注对象。
- 抖动(Thrashing):在内存极度不足的情况下,系统可能会陷入“抖动”状态:不断地换出页面,但这些页面很快又被需要,于是又被换入,导致系统大部分时间都在进行I/O而不是有用的计算。
- LRU的局限性:经典的LRU对某些访问模式(如大文件顺序扫描)不友好,可能做出错误的回收决策。这也是MGLRU试图解决的问题。
- 复杂性与调优:页面回收的逻辑非常复杂,并且有多个
sysctl参数可以调整其行为。不正确的调优可能会导致性能下降。
使用场景
在哪些具体的业务或技术场景下,它是首选解决方案?
由于vmscan.c是内核的核心机制,它没有“可选”的场景,而是在以下场景中其行为表现至关重要:
- 内存密集型应用:数据库(如MySQL, PostgreSQL)、内存缓存(Redis, Memcached)、大数据处理(Spark)等,这些应用会消耗大量内存,并持续对页面回收机制构成压力。
- 文件服务器:文件服务器会大量使用页缓存(page cache)来加速文件访问。当内存不足时,
vmscan.c负责从页缓存中回收旧的文件页面。 - 资源受限的系统:在嵌入式设备或小型虚拟机中,物理内存非常有限,页面回收机制被激活的频率会更高。
是否有不推荐使用该技术的场景?为什么?
不能“不使用”该技术,但可以避免其最坏情况的发生。在某些场景下,应该通过其他方式管理内存,以避免触发昂贵的回收路径:
- 硬实时系统:硬实时系统无法容忍直接回收带来的不可预测的延迟。这类系统通常会通过内存锁定(
mlock())等技术将关键内存锁定在RAM中,防止其被回收。 - 超低延迟应用:在高频交易等场景中,任何由直接回收或缺页中断(page fault)引起的延迟都是不可接受的。这些应用通常会预先分配并锁定所有需要的内存。
对比分析
请将其 与 其他相似技术 进行详细对比。
vmscan.c(页面回收)与OOM Killer(Out-of-Memory Killer)是内核处理内存压力的两个不同阶段的机制。
| 特性 | 页面回收 (Page Reclaim, vmscan.c) |
OOM Killer (mm/oom_kill.c) |
|---|---|---|
| 功能概述 | 优雅地、渐进地释放内存。通过回收单个页面或小批量页面来缓解内存压力。 | 粗暴地、最后的手段。当页面回收也无法满足内存分配请求时,选择一个进程并将其杀死,以一次性释放其占用的所有内存。 |
| 触发时机 | 内存水位低于预设的阈值时,由kswapd或直接分配路径触发。是常规的、预期的内存管理活动。 |
当页面回收和所有其他尝试都失败后,在内存分配的最终环节被触发。是异常的、失败的标志。 |
| 实现方式 | 复杂的算法,扫描LRU链表,进行页面老化、写回、交换等操作。 | 根据一系列启发式规则(如进程的内存占用、oom_score_adj值等)计算每个进程的“牺牲”分数,并杀死分数最高的进程。 |
| 对系统的影响 | 性能影响。可能导致I/O增高、应用程序延迟增加。 | 服务中断。被杀死的进程会丢失所有未保存的状态,导致服务中断或应用程序崩溃。 |
| 目标 | 维持系统运行。通过“腾挪”内存空间来满足需求,保持系统稳定。 | 避免系统崩溃。在无法满足一个关键的内存请求(可能来自内核自身)时,通过牺牲一个进程来保全整个系统。 |
kswapd_init 与内存回收线程的启动和配置
本代码片段负责初始化 Linux 内核核心的内存回收机制。其核心功能是为系统中的每一个 NUMA 内存节点(Memory Node)启动一个专用的内核守护线程 kswapd。该线程在后台运行,负责在系统内存不足时扫描并回收内存页,以释放空间供新的分配请求使用。此外,代码还通过 sysctl 在 /proc/sys/vm/ 目录下创建了用于调整内存回收行为的配置文件,如 swappiness。
实现原理分析
该机制的实现围绕着内核线程的动态创建、NUMA 架构的感知以及通过 sysctl 提供的运行时可调优性。
基于 NUMA 节点的线程管理 (
kswapd_run,kswapd_stop):- Linux 内核为每个物理内存节点(由
pg_data_t结构体表示,nid为其ID)都配备一个独立的kswapd线程。这种设计确保了内存回收操作可以在本地节点上进行,减少了跨节点内存访问的开销,从而在 NUMA 系统上获得更好的性能。 kswapd_run函数是启动线程的核心。它首先检查pgdat->kswapd指针,确保每个节点只启动一个实例(幂等性)。然后,它调用kthread_create_on_node来创建一个新的内核线程,该线程执行kswapd函数(未在此代码段中显示)。关键在于,该线程被明确地绑定到指定的内存节点nid上。kswapd_stop函数则与之对应,用于在内存节点被热拔除(hot-removed)时,安全地停止并清理该节点上的kswapd线程。
- Linux 内核为每个物理内存节点(由
启动时自动初始化 (
kswapd_init):- 此函数通过
module_init宏注册,确保在内核启动过程中被自动调用。 - 它首先调用
swap_setup()初始化交换子系统(即使没有交换分区,此步骤也是必要的)。 - 然后,它使用
for_each_node_state(nid, N_MEMORY)宏来遍历系统中所有当前存在的内存节点,并对每一个节点调用kswapd_run,从而为整个系统启动所有必要的内存回收线程。 - 最后,它调用
register_sysctl_init将vmscan_sysctl_table注册到sysctl树中,创建/proc/sys/vm/swappiness等配置文件。
- 此函数通过
运行时可调参数 (
vmscan_sysctl_table):swappiness: 这是一个关键的性能调优参数(0-200),它控制了内核在进行内存回收时,回收文件页(Page Cache)与回收匿名页(Anonymous Pages,如进程堆栈)之间的倾向性。高值倾向于回收匿名页(即进行交换),低值则倾向于回收文件页。zone_reclaim_mode(仅限 NUMA): 控制当一个节点内存不足时,是从远程节点分配内存还是在本地节点内进行更积极的回收。
特定场景分析:单核、无MMU的STM32H750平台
功能相关性与 kswapd 的角色变化
- 核心作用: 在 STM32H750 这样的微控制器上,通常没有硬盘等块设备作为交换(Swap)空间。此外,无MMU的Linux (uClinux) 无法实现真正的匿名页换出,因为无法通过缺页异常来将页面换回。因此,
kswapd的“交换”功能(swapping dirty anonymous pages)在此平台上是无效的。 - 剩余的关键角色: 尽管如此,
kswapd仍然扮演着至关重要的页面回收(Page Reclaiming)角色。当系统内存耗尽时,kswapd会被唤醒来扫描并回收那些“干净”的、可以被安全丢弃的内存页。在无MMU的STM32H750上,这主要指的是文件页缓存(Page Cache)。例如,如果系统从外部Flash的文件系统中读取了可执行文件或数据文件到RAM中,当RAM紧张时,kswapd可以释放这些缓存页,因为它们可以按需从原始Flash中重新读取。这个机制是防止系统因内存耗尽而崩溃(OOM Killer)的关键防线。
NUMA 架构的简化
- STM32H750 是一个典型的UMA (Uniform Memory Access) 架构,它只有一个内存控制器和一块统一的内存区域。因此,在Linux内核看来,它只有一个内存节点,即 Node 0 (
nid=0)。 - 这意味着
for_each_node_state循环只会执行一次。整个系统将只会创建一个kswapd0内核线程。所有NUMA相关的复杂性都退化为最简单的单节点情况。CONFIG_NUMA宏在此平台上通常是未定义的,因此zone_reclaim_mode这个sysctl条目也不会被编译进去。
swappiness 的意义
- 即使没有交换空间,
swappiness参数在 STM32H750 上仍然有意义。它在这里控制的是内核回收文件页缓存的积极性。设置为 0 (vm_swappiness = 0) 会让内核尽可能地保留文件页缓存,只有在万不得已时才回收它们。对于需要频繁访问文件系统(如从SD卡或QSPI Flash运行应用)的场景,这可能不是最佳选择。适当提高swappiness的值可以使内核在内存压力下更愿意释放文件缓存,为新的内存分配腾出空间。
代码分析
1 | /** |
 微信
微信- 支付寶








