CANopene Heartbeat运行流程
@[toc]
1 | flowchart LR |
先给结论
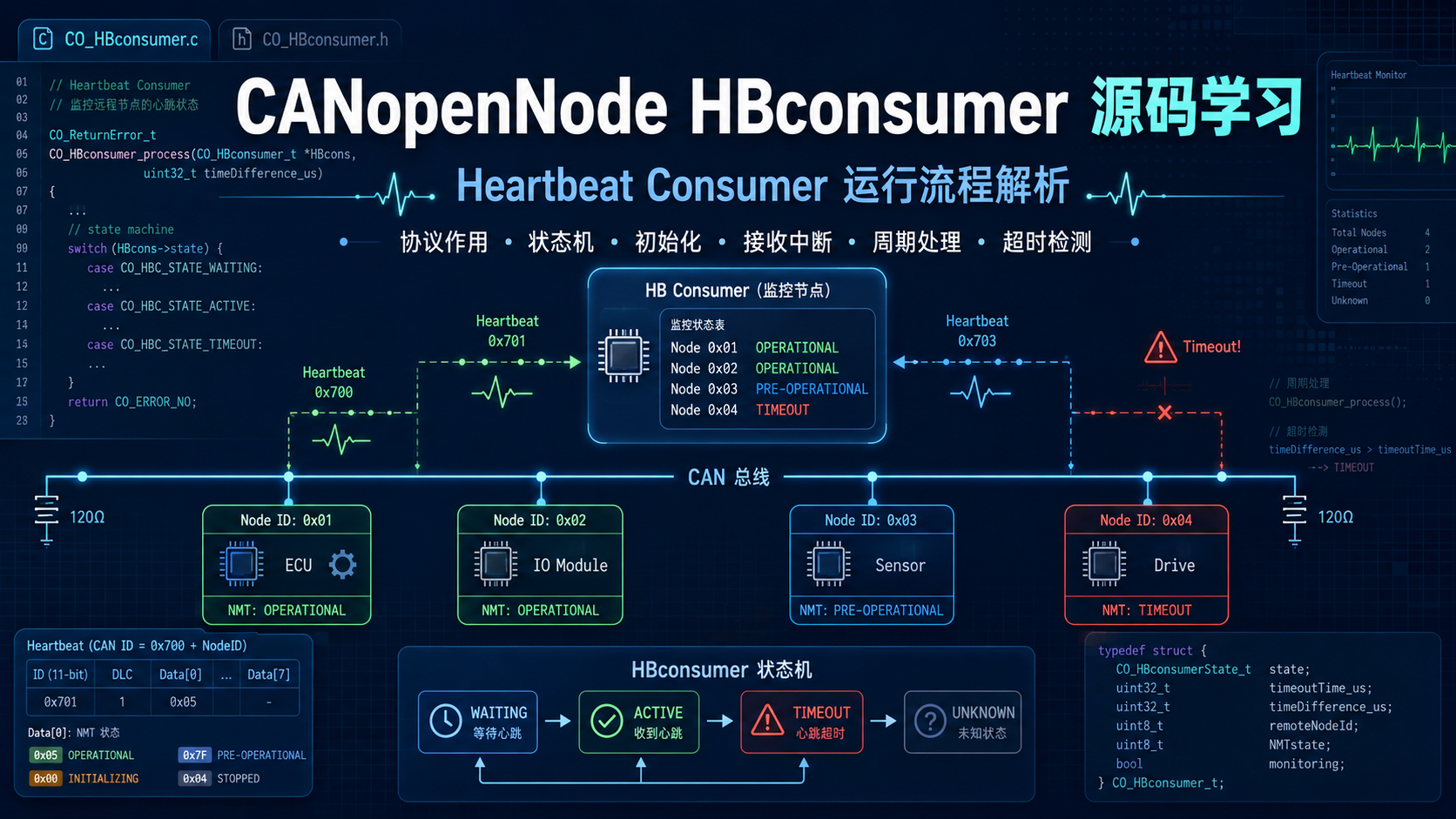
Heartbeat Consumer 的本质是:本节点用对象字典 0x1016 配置要监控的远端节点,然后监听远端节点按 0x700 + Node-ID 发出的 1 字节 Heartbeat;如果已开始监控后在规定时间内没收到下一帧,就把该远端节点判为 heartbeat timeout,并通过 Emergency 模块上报错误。
在 CANopenNode 的 CO_HBconsumer.c/h 中,这条链路可以压缩成:
1 | OD 0x1016 sub-index 写入/初始化 |
这里最重要的分工是:CAN 接收回调只做“收到了什么”的预处理;真正的状态机、超时判断、EMCY 上报都在 CO_HBconsumer_process() 中完成。
1. 协议先行:Heartbeat Consumer 解决什么问题
CANopen 的 NMT 负责节点通信状态管理,Heartbeat 则是错误控制的一部分:远端节点作为 heartbeat producer 周期性广播自己的 NMT 状态;本节点作为 heartbeat consumer 接收这些状态并判断远端节点是否还在线、是否处于期望状态。
CiA 对 NMT 的公开说明中,NMT 状态机包含 Initialization、Pre-operational、Operational、Stopped;设备初始化完成后会进入 Pre-operational,并通过 boot-up message 表示已经准备好工作。NMT 命令本身由 active NMT manager 发送,CAN-ID 为 0x000,数据长度为 2 字节,byte0 是命令,byte1 是目标 Node-ID,Node-ID 为 0 表示所有节点。[^cia-nmt]
Heartbeat 与 NMT 的关系是:Heartbeat 的 1 字节数据就是远端节点当前的 NMT state。 常见状态值如下:
| Byte0 | 含义 | 在源码中的典型名字 |
|---|---|---|
0x00 |
boot-up / Initializing | CO_NMT_INITIALIZING |
0x04 |
Stopped | CO_NMT_STOPPED |
0x05 |
Operational | CO_NMT_OPERATIONAL |
0x7F |
Pre-operational | CO_NMT_PRE_OPERATIONAL |
Heartbeat 的 CAN 帧格式很小:
| 字段 | 值 |
|---|---|
| CAN-ID / COB-ID | 0x700 + producer Node-ID |
| DLC | 1 |
| Byte0 | producer 当前 NMT state |
对于 consumer 来说,核心配置在 0x1016 Consumer heartbeat time;对于 producer 来说,核心配置在 0x1017 Producer heartbeat time。0x1016 的一个子项是 32 位值,高 16 位给出 producer Node-ID,低 16 位给出 expected time,单位为 ms。consumer 必须在该时间窗内收到被监控 producer 的 heartbeat,否则产生 heartbeat event。[^kollmorgen-hb]
2. 0x1016 与 0x1017:不要把“我监控别人”和“我发心跳”混在一起
1 | flowchart LR |
| 对象 | 所在节点 | 方向 | 作用 |
|---|---|---|---|
0x1017 Producer heartbeat time |
被监控节点 | 发出 | 规定该节点多久广播一次自己的 heartbeat |
0x1016 Consumer heartbeat time |
监控者节点 | 接收 | 规定本节点要监听哪个 producer,以及多久收不到算超时 |
一个典型配置是:
1 | 远端节点 3:0x1017 = 10 ms -> 每 10 ms 发一次 heartbeat |
通常 consumer 的 expected time 应设置得比 producer 的发送周期稍长,给 CAN 调度、主循环抖动和短时仲裁延迟留余量。公开设备文档也给出类似建议:producer 的 heartbeat 输出周期应略短于 consumer 的 expected time。[^kollmorgen-hb]
3. CANopenNode 里 CO_HBconsumer_t 保存了哪些状态
CO_HBconsumer.h 中有两层结构:
CO_HBconsumer_t:整个 Heartbeat Consumer 对象。CO_HBconsNode_t:数组中的一个被监控远端节点。
1 | flowchart LR |
3.1 每个被监控节点的状态
CO_HBconsumer_state_t 有 4 个状态:
| 状态 | 触发条件 | 含义 |
|---|---|---|
CO_HBconsumer_UNCONFIGURED |
nodeId == 0 或 consumerTime == 0 |
该子项未启用,不监控 |
CO_HBconsumer_UNKNOWN |
已配置但未收到有效 heartbeat,或收到 boot-up 后等待下一帧 | 还不能确认远端在线 |
CO_HBconsumer_ACTIVE |
收到非 boot-up heartbeat,且未超时 | 远端 heartbeat 正常 |
CO_HBconsumer_TIMEOUT |
已 active 后超过 time_us 未收到下一帧 |
远端 heartbeat 超时 |
源码中的关键成员可以按用途分成几组:
| 成员 | 用途 |
|---|---|
nodeId |
被监控 producer 的 Node-ID |
NMTstate |
最近一次 heartbeat 的 Byte0,即远端 NMT state |
HBstate |
本 consumer 对该远端节点的监控状态 |
timeoutTimer |
自上次 heartbeat 后累计的时间 |
time_us |
从 0x1016 低 16 位转换得到的超时时间,单位 us |
CANrxNew |
CAN 接收回调置位,process() 读取后清零 |
| 回调函数指针 | 可选:pre callback、NMT changed、heartbeat started、timeout、remote reset |
CO_HBconsumer_t 还维护两个聚合标志:
| 成员 | 含义 |
|---|---|
allMonitoredActive |
所有已配置节点都处于 ACTIVE,或者没有节点被监控 |
allMonitoredOperational |
所有已配置节点的 NMTstate 都是 CO_NMT_OPERATIONAL,或者没有节点被监控 |
这两个标志适合应用层做“所有关键节点都在线/都进入 Operational 了吗”的快速判断。
4. 初始化流程:从 0x1016 到 CAN RX buffer
1 | flowchart TD |
CO_HBconsumer_init() 必须在 communication reset 阶段调用。它主要做 5 件事。
4.1 绑定外部资源
函数先校验参数,然后清零 CO_HBconsumer_t,绑定:
1 | HBcons->em -> Emergency 对象 |
注意:monitoredNodes 数组由外部提供,CANopenNode 不在 CO_HBconsumer_init() 里为它动态分配内存。
4.2 计算实际监控项数量
源码取下面两者的较小值:
1 | OD_1016_HBcons->subEntriesCount - 1 |
这表示:对象字典里配置了多少个 0x1016 子项是一层上限,外部数组容量又是一层上限。
4.3 逐项读取 0x1016
对每个子索引:
1 | val = OD_get_u32(OD_1016_HBcons, i + 1U, ...); |
这里 consumer_time 单位是 ms;进入 CO_HBconsumer_initEntry() 后会乘以 1000U 转成 time_us。
4.4 CO_HBconsumer_initEntry() 配置一个监控项
该函数做了几个关键判断:
- 参数为空或
idx越界,返回非法参数。 - 如果
consumerTime_ms != 0且nodeId != 0,检查是否有重复 nodeId。 - 若
nodeId != 0且time_us != 0:COB_ID = 0x700 + nodeIdHBstate = CO_HBconsumer_UNKNOWN
- 否则:
COB_ID = 0time_us = 0HBstate = CO_HBconsumer_UNCONFIGURED
- 最后调用
CO_CANrxBufferInit(),把 CAN 接收过滤器和CO_HBcons_receive()回调绑定起来。
4.5 动态写 0x1016
如果启用了 CO_CONFIG_FLAG_OD_DYNAMIC,CO_HBconsumer_init() 会给 0x1016 安装 OD extension。之后应用或 SDO 写 0x1016 时,OD_write_1016() 会重新解析 32 位值并调用 CO_HBconsumer_initEntry(),从而动态改变被监控节点和接收过滤器。
这也是为什么 CO_CONFIG_HB_CONS 默认包含 CO_CONFIG_GLOBAL_FLAG_OD_DYNAMIC:调试或主站配置阶段可以直接通过对象字典改变监控关系。
5. 接收回调:中断上下文只做轻量预处理
1 | flowchart LR |
CO_HBcons_receive() 是 CAN RX 回调。它只接受 DLC 为 1 的帧:
1 | if (DLC == 1U) { |
这段代码有两个设计点:
- 不在 CAN 回调里判断超时、不上报 EMCY、不做复杂状态机。
- 只把最新的 NMT state 和
CANrxNew标志交给周期处理函数。
如果启用了 CO_CONFIG_FLAG_CALLBACK_PRE,收到 heartbeat 后可以调用 pre callback。这个回调常用于 RTOS 场景下唤醒处理 CO_HBconsumer_process() 的任务。
6. 主处理流程:CO_HBconsumer_process() 真正运行状态机
1 | flowchart TD |
CO_HBconsumer_process() 周期调用,入参有 3 个关键量:
| 参数 | 作用 |
|---|---|
NMTisPreOrOperational |
本节点当前是否处于 Pre-operational 或 Operational |
timeDifference_us |
距离上次调用过去了多少 us |
timerNext_us |
可选:告诉上层下一次最晚多久后需要再次调用 |
6.1 本节点 NMT 状态门控
源码只有在下面条件为真时,才执行正常监控逻辑:
1 | if (NMTisPreOrOperational && HBcons->NMTisPreOrOperationalPrev) { |
也就是本节点需要连续处于 Pre-operational 或 Operational。若刚进入或刚离开这些状态,源码会清理每个监控项:
1 | NMTstate = CO_NMT_UNKNOWN |
这能避免本节点 NMT 状态切换边界上的旧 heartbeat 状态被误用。
6.2 有新帧:先区分 boot-up 和 heartbeat
对每个已配置节点,process() 先看 CANrxNew。
如果 NMTstate == CO_NMT_INITIALIZING,这帧被视为 boot-up message:
1 | 可选调用 remote reset callback |
这里有一个关键点:boot-up 不会把节点变成 ACTIVE。 它只说明远端刚启动或通信刚复位,consumer 会回到 UNKNOWN,等待后续第一帧真正的 heartbeat。
如果 NMTstate != CO_NMT_INITIALIZING,这帧才被视为正常 heartbeat:
1 | 如果此前不是 ACTIVE:可选调用 heartbeat started callback |
timeDifference_us_copy = 0 的目的,是避免“刚收到新 heartbeat 的同一轮 process 又把本轮 delta 加到 timeoutTimer 上”。
6.3 无新帧或处理完新帧后:检查超时
只有 HBstate == ACTIVE 时,源码才累加 timeoutTimer:
1 | timeoutTimer += timeDifference_us_copy |
如果:
1 | timeoutTimer >= time_us |
就执行 timeout 处理:
1 | 可选调用 timeout callback |
这说明:未收到第一帧 heartbeat 前不会超时;只有进入 ACTIVE 后,consumer 才开始计时。 CANopenNode 官方文档也明确写到,monitoring starts after the reception of the first HeartBeat, not bootup。[^canopennode-hbc]
1 | flowchart LR |
6.4 聚合状态和 NMT changed callback
每轮遍历时,源码会同步计算:
1 | allMonitoredActiveCurrent |
判断规则很直接:
1 | 只要有一个已配置节点不是 ACTIVE,allMonitoredActiveCurrent = false |
如果启用了 CO_CONFIG_HB_CONS_CALLBACK_CHANGE 或 CO_CONFIG_HB_CONS_CALLBACK_MULTI,源码还会比较:
1 | monitoredNode->NMTstate != monitoredNode->NMTstatePrev |
变化时触发 NMT changed callback,然后更新 NMTstatePrev。
6.5 所有节点恢复 active 后清错误
源码最后有一段容易忽略:
1 | if (!HBcons->allMonitoredActive && allMonitoredActiveCurrent) { |
含义是:当系统从“不是所有被监控节点都 active”变为“所有被监控节点都 active”时,清除 heartbeat consumer timeout 和 remote reset 相关错误。
源码注释也提醒:Heartbeat consumer 对所有被监控节点共用一个 emergency index,所以 reset 时用 0 清该类错误;而 report 时用循环下标 i 作为 info code,便于定位是哪一个 0x1016 子项对应的节点。
7. 回调配置:公共回调与每节点回调不能同时启用
CO_config.h 对 Heartbeat Consumer 的配置宏做了分层:
| 宏/flag | 作用 |
|---|---|
CO_CONFIG_HB_CONS_ENABLE |
编译并启用 Heartbeat Consumer |
CO_CONFIG_HB_CONS_CALLBACK_CHANGE |
启用“公共 NMT state changed 回调” |
CO_CONFIG_HB_CONS_CALLBACK_MULTI |
启用每个被监控节点独立的多类回调 |
CO_CONFIG_HB_CONS_QUERY_FUNCT |
启用查询函数:按 Node-ID 或 idx 查状态 |
CO_CONFIG_FLAG_CALLBACK_PRE |
收到 heartbeat 后先调用轻量 pre callback |
CO_CONFIG_FLAG_TIMERNEXT |
在 process() 中计算 timerNext_us |
CO_CONFIG_FLAG_OD_DYNAMIC |
写 0x1016 时动态重配置监控项 |
CO_HBconsumer.c 明确禁止同时启用:
1 | CO_CONFIG_HB_CONS_CALLBACK_CHANGE |
原因是这两种回调模型一个是公共回调,一个是每节点回调,语义上互斥。
CALLBACK_MULTI 打开后可以分别注册:
| 回调 | 触发时机 |
|---|---|
CO_HBconsumer_initCallbackNmtChanged() |
远端 NMT state 变化 |
CO_HBconsumer_initCallbackHeartbeatStarted() |
consumer 从非 ACTIVE 收到有效 heartbeat,转入 ACTIVE |
CO_HBconsumer_initCallbackTimeout() |
ACTIVE 后超时 |
CO_HBconsumer_initCallbackRemoteReset() |
收到 boot-up,识别到远端复位/通信复位 |
8. 查询接口:只在启用 CO_CONFIG_HB_CONS_QUERY_FUNCT 时存在
如果打开 CO_CONFIG_HB_CONS_QUERY_FUNCT,源码会编译 3 个查询函数:
| 函数 | 用途 |
|---|---|
CO_HBconsumer_getIdxByNodeId() |
用 producer Node-ID 查 monitoredNodes[] 下标 |
CO_HBconsumer_getState() |
用 idx 查询当前 CO_HBconsumer_state_t |
CO_HBconsumer_getNmtState() |
用 idx 查询远端 NMT state |
其中 CO_HBconsumer_getNmtState() 有一个约束:只有该节点 HBstate == CO_HBconsumer_ACTIVE 时,返回的 NMT state 才有效;否则返回 -1。
这与协议语义一致:如果没收到有效 heartbeat,或者已经 timeout,远端 NMT 状态就是未知的。
9. STM32/RTOS 工程里怎么接入这段逻辑
在 CANopenNode 工程里,Heartbeat Consumer 通常不是普通从机最小配置必须项。普通 STM32 从机通常先需要:
1 | NMT slave + Heartbeat producer + SDO server + EMCY producer + PDO + OD |
只有当本节点还需要监控主站或其他从站时,才需要打开 Heartbeat Consumer。
最小接入路径如下:
1 | 1. CO_config.h 中打开 CO_CONFIG_HB_CONS_ENABLE |
在 RTOS 中,如果启用了 CO_CONFIG_FLAG_CALLBACK_PRE,可以让 CO_HBcons_receive() 在收到 CAN 帧后唤醒任务;但仍建议把真正处理放在任务上下文,不要在 CAN 接收中断中直接做复杂业务。
10. 调试时重点看这几类现象
| 现象 | 优先检查 |
|---|---|
一直是 UNCONFIGURED |
0x1016 子项是否为 0;Node-ID 或 time 是否为 0 |
一直是 UNKNOWN |
是否只收到 boot-up;producer 的 0x1017 是否启用;CAN-ID 是否为 0x700 + Node-ID |
一进入 ACTIVE 很快 timeout |
0x1016 expected time 是否太短;主循环周期是否太长;producer 周期是否比 consumer expected time 短 |
| 收到帧但没有处理 | CO_HBconsumer_process() 是否周期调用;本节点是否连续处于 Pre-operational/Operational |
写 0x1016 后没生效 |
是否启用 CO_CONFIG_FLAG_OD_DYNAMIC;写入值是否触发 OD_write_1016() |
allMonitoredOperational 一直 false |
被监控节点可能只是 Pre-operational;它必须上报 CO_NMT_OPERATIONAL 才会为 true |
| 远端复位后没有 timeout | 收到 boot-up 后源码把状态置为 UNKNOWN,监控等待下一帧 heartbeat;这不是普通 timeout 路径 |
11. 一句话总结
CO_HBconsumer.c/h 的主线不是“收到 heartbeat 就保存一下”这么简单,而是:用 0x1016 建立本节点对远端 producer 的监控表,用 CAN RX 回调捕获 0x700 + Node-ID 的 1 字节 NMT state,再由 CO_HBconsumer_process() 周期性完成 boot-up 识别、ACTIVE/TIMEOUT 状态转换、NMT 状态变化回调、聚合在线状态,以及 heartbeat 相关 Emergency 上报与恢复清除。
参考资料
[^canopennode-hbc]: CANopenNode 官方 Doxygen,Heartbeat consumer:https://canopennode.github.io/CANopenNode/group__CO__HBconsumer.html
[^canopennode-github]: CANopenNode GitHub 仓库说明:https://github.com/CANopenNode/CANopenNode
[^canopennode-config]: CANopenNode CO_config.h Doxygen/GitHub:https://github.com/CANopenNode/CANopenNode/blob/master/301/CO_config.h
[^cia-nmt]: CAN in Automation,Network management:https://www.can-cia.org/can-knowledge/network-management
[^kollmorgen-hb]: Kollmorgen AKD2G CANopen Heartbeat 文档:https://webhelp.kollmorgen.com/akd2g/english/content/AKD2G%20CANopen/CANopen_06_04_08%20Heartbeat.htm
[^deditec-1016]: DEDITEC,0x1016 Consumer Heartbeat Time:https://www.deditec.de/media/manuals/en/manual_cos_serie/0x1016-consumer-heartbeat-time.htm
本地材料:CO_HBconsumer.h、CO_HBconsumer.c、CO_NMT_Heartbeat.h、CO_config.h、CiA301 V4.2.0(中文注释版).pdf。
 微信
微信- 支付寶









