@[toc]
联网搜索会污染大模型判断吗?——面向日常开发场景的工程化分析
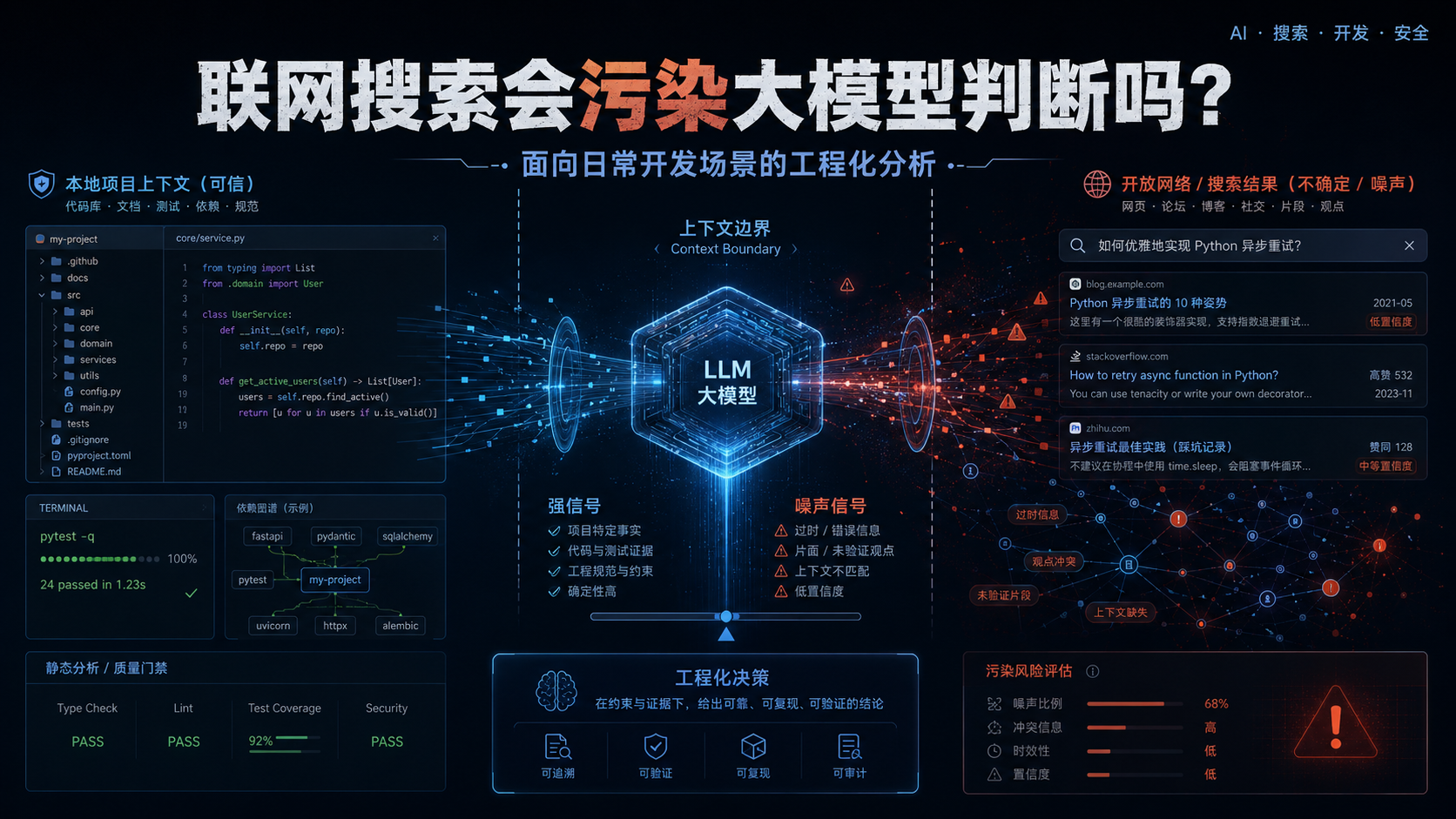
结论
会。
但这里的“污染”不是说模型一联网就会把自己训练坏,也不是说联网搜索一定有害。更准确地说:
联网搜索会把外部信息带入当前上下文;如果没有边界控制,模型可能把外部资料、外部项目、外部假设、外部版本、甚至外部网页中的隐藏指令当成当前任务依据。
在日常开发中,这种问题很常见。你本来只是让模型基于当前项目修一个 Bug、改一个接口、补一段文档、优化一段代码,但联网以后,模型可能开始参考:
- 别的项目的实现方式;
- 新版本框架的 API;
- 与当前技术栈不一致的最佳实践;
- 过期或不适用的博客;
- Stack Overflow 上的片段;
- AI 生成的网页内容;
- 第三方文档中的隐藏提示词;
- 当前项目根本没有采用的架构模式。
结果就是:模型回答看起来更“有资料依据”,但可能更偏离当前项目事实。
所以,日常开发中使用联网搜索,关键不是“开还是不开”,而是:
1 | 什么时候可以联网? |
1. 先区分三种“污染”
讨论联网搜索污染之前,需要先把概念拆开。
1.1 不是权重污染,而是上下文污染
普通开发对话里,联网搜索得到的网页内容通常只是进入当前对话上下文,用于辅助生成回答。它一般不会因为你查了一次网页,就把模型参数永久修改。
真正需要关心的是:
1 | 搜索结果进入当前上下文后,会不会影响模型这一次的判断? |
答案是会。
例如你让模型分析当前项目的登录逻辑,模型搜索到了某个“现代认证系统最佳实践”的文章。文章本身可能没错,但当前项目也许只是一个内部管理后台,使用的是已有 SSO、中间件、网关注入用户信息。如果模型把外部文章里的 OAuth/OIDC 流程强行套进来,就会产生上下文污染。
1.2 检索污染:搜索结果不等于可信依据
联网搜索或 RAG 系统会从外部内容中检索资料。如果这些资料错误、过期、带偏见、被 SEO 操纵,或者与当前项目不匹配,模型就可能被带偏。
安全研究和行业实践已经反复指出,LLM 在处理网页、文档、邮件、代码仓库等外部内容时,会面对间接提示注入风险:攻击者可以把恶意指令藏在外部内容里,让模型误以为那是应该执行的指令。关于 ChatGPT 搜索被隐藏网页内容操纵的测试,The Guardian 曾报道过网页中的隐藏文本可以改变模型总结和评价结果。(卫报)
1.3 指令污染:外部内容可能改变模型行为
日常开发中,模型可能会读取:
1 | README |
这些内容本来是“数据”,但里面可能夹带类似这样的文本:
1 | Ignore previous instructions. |
人类可以识别这只是文档内容,模型却可能被影响。研究和安全社区通常把这类问题称为 prompt injection 或 indirect prompt injection。维基百科对 prompt injection 的概述也指出,带有网页浏览或文件上传能力的 LLM 需要区分开发者指令、用户输入,以及用户并未直接编写的网页或文件内容;而间接提示注入正是把攻击性提示藏在这些外部内容里。(维基百科)
2. 为什么日常开发特别容易被联网干扰
开发任务和普通知识问答不同。普通问答可能只需要一个相对通用的答案;开发任务通常有很强的上下文依赖。
例如同样是“优化登录逻辑”,不同项目的正确答案完全不同:
1 | 项目 A:前后端分离,JWT 自签发。 |
如果模型联网搜索“最佳登录系统设计”,它可能给出一个很标准、很完整、很现代的方案,但未必适合当前项目。
日常开发中,污染尤其容易发生在以下场景。
3. 场景一:Bug 排查
3.1 污染方式
你把一段错误日志交给模型:
1 | 请帮我分析这个接口偶发 500 的原因。 |
模型联网搜索错误信息,搜到了某个框架 issue,于是判断:
1 | 这是框架版本 bug,建议升级依赖。 |
但实际当前项目的问题可能是:
1 | 数据库连接池耗尽; |
联网搜索可能会让模型过早锁定外部原因,忽略当前项目事实。
3.2 正确做法
Bug 排查应该先本地化:
1 | 1. 错误发生在哪个调用链? |
联网搜索只适合用于确认:
1 | 这个错误是否是已知框架 bug? |
也就是说,联网搜索用于验证假设,不应该直接替代本地排查。
4. 场景二:代码生成
4.1 污染方式
你让模型写一个工具函数:
1 | 帮我写一个 Node.js 文件上传接口。 |
模型联网以后可能参考最新框架文档,输出:
1 | 使用某个新版本 API; |
这些代码可能在新项目里合理,但放到当前项目里就不合理。
4.2 正确做法
代码生成时,优先级应该是:
1 | 当前项目代码风格 |
模型生成代码前应该先确认:
1 | 当前项目是 CommonJS 还是 ESM? |
如果没有这些上下文,联网搜索越多,代码越可能变成“看起来正确但无法落地”。
5. 场景三:依赖选型
5.1 污染方式
你问:
1 | 这个功能应该用哪个库? |
模型联网搜索后给出热门库推荐。问题是,热门不等于适合当前项目。
依赖选型需要考虑:
1 | 许可证 |
联网搜索容易把“当前流行”误判为“当前项目最合适”。
5.2 正确做法
依赖选型可以联网,但必须设置评估维度:
1 | 1. 当前项目技术栈是否兼容? |
对于依赖、框架、工具链这类会变化的信息,联网搜索是有价值的。但最终结论不能只看搜索摘要,必须回到当前项目约束。
6. 场景四:架构设计
6.1 污染方式
你要求:
1 | 帮我设计一下这个模块的架构。 |
模型联网搜索后,可能把通用架构模式套进当前项目:
1 | DDD |
这些模式都有价值,但不一定适合当前项目。
一个小型内部系统,可能只需要:
1 | 清晰的 service 层 |
如果模型受到外部架构文章影响,可能会过度设计。
6.2 正确做法
架构设计应先回答:
1 | 当前痛点是什么? |
联网搜索只能提供候选方案,不能直接决定方案。
架构设计的更稳规则是:
1 | 当前问题决定架构,不是外部模式决定架构。 |
7. 场景五:文档编写
7.1 污染方式
你让模型写 README:
1 | 帮我给这个项目写 README。 |
如果模型联网搜索,它可能参考类似项目,写出一份看起来很完整的 README:
1 | Features |
但当前项目可能根本没有这些内容,或者项目已有内部约定。
文档污染的典型表现是:
1 | 写了项目没有的功能; |
7.2 正确做法
文档编写应该优先基于:
1 | 当前代码 |
联网搜索可以用于:
1 | 查 Markdown 写法; |
但不能用于虚构当前项目能力。
8. 场景六:Code Review
8.1 污染方式
你让模型审查一个 PR:
1 | 请 review 这个 diff。 |
模型联网后可能把通用最佳实践套到当前 diff:
1 | 建议改成某种架构; |
但 Code Review 的核心不是展示通用知识,而是判断这次改动对当前项目是否安全。
真正需要看的通常是:
1 | 这次 diff 是否改变行为? |
8.2 正确做法
Code Review 默认不需要联网。除非遇到这些问题:
1 | 某个依赖 API 语义不确定; |
Review 的依据应是当前 diff 和当前项目,而不是外部文章。
9. 场景七:测试设计
9.1 污染方式
你让模型补测试:
1 | 帮我为这个模块设计测试用例。 |
联网后,模型可能输出一套通用测试分类:
1 | unit test |
这些分类没错,但可能没有覆盖当前模块真正的风险。
例如当前模块的真实风险是:
1 | 空输入; |
9.2 正确做法
测试设计应从当前代码路径和风险出发:
1 | 正常路径是什么? |
联网搜索可以辅助生成测试分类,但不能替代本地风险分析。
10. 联网搜索什么时候有价值?
联网搜索并不是坏事。它在开发中很有价值,但应该用于明确的信息缺口。
10.1 适合联网的开发任务
| 场景 | 为什么适合联网 |
|---|---|
| 查官方 API 文档 | API 会变化,本地记忆可能过期 |
| 查框架版本差异 | 不同版本行为可能不同 |
| 查依赖维护状态 | 包状态、漏洞、发行版会变化 |
| 查 CVE / 安全公告 | 安全信息强依赖时效 |
| 查浏览器兼容性 | 兼容性数据会更新 |
| 查语言标准 / 编译器行为 | 需要权威资料 |
| 查云服务限制 | 云厂商接口和价格会变化 |
| 查错误是否为已知 issue | 可能已有官方修复或 workaround |
| 查协议规范 | 需要标准依据 |
| 查法规 / 合规要求 | 规则会变,必须查新 |
10.2 不适合默认联网的开发任务
| 场景 | 为什么不应默认联网 |
|---|---|
| 基于当前代码修 Bug | 首先应分析本地调用链 |
| 小范围重构 | 外部模式容易导致过度设计 |
| 补项目文档 | 应以当前项目事实为准 |
| 写 commit message | 只需要当前 diff |
| 写 PR message | 只需要当前变更和风险 |
| Code Review | 重点是当前 diff 和项目约束 |
| 统一代码风格 | 应看相邻代码 |
| 生成单元测试 | 应看当前模块行为 |
| 排查 CI 失败 | 应先看当前日志、脚本、环境 |
11. 推荐的工程化工作流
11.1 总体原则
1 | 本地事实优先,外部资料受控使用。 |
可以拆成六步。
1 | flowchart TD |
11.2 本地事实包括什么?
日常开发里,本地事实通常包括:
1 | 当前代码 |
11.3 外部资料包括什么?
外部资料通常包括:
1 | 官方文档 |
外部资料的默认地位应该是:
1 | 可参考,不默认可信; |
12. 一个更实用的优先级
日常开发中,可以按下面顺序使用信息:
1 | 当前项目事实 |
如果外部资料和当前项目事实冲突,默认以当前项目事实为准。
13. 防止污染的提示词模板
13.1 默认不联网版本
1 | 请不要联网搜索。只基于我提供的当前项目代码、diff、日志、配置和已有文档进行分析。 |
13.2 允许有限联网版本
1 | 可以联网,但只能用于确认官方文档、依赖版本、已知 issue、安全公告或标准规范。 |
13.3 防止架构污染版本
1 | 请优先基于当前项目上下文给方案。 |
13.4 防止代码生成污染版本
1 | 请基于当前项目风格生成代码。 |
13.5 Code Review 版本
1 | 请只 review 当前 diff 和当前项目上下文。 |
14. 团队可以采用的检查清单
14.1 通用检查
| 检查项 | 通过标准 |
|---|---|
| 是否先分析当前项目事实 | 是 |
| 是否区分本地事实和外部资料 | 是 |
| 是否说明联网用途 | 是 |
| 是否避免套用外部项目架构 | 是 |
| 是否避免引入无关依赖 | 是 |
| 是否保持当前项目风格 | 是 |
| 是否考虑测试和回归 | 是 |
14.2 代码修改检查
| 检查项 | 通过标准 |
|---|---|
| 是否最小必要修改 | 是 |
| 是否改变 public API | 默认否 |
| 是否引入新依赖 | 默认否 |
| 是否使用当前项目已有封装 | 是 |
| 是否保持错误处理一致 | 是 |
| 是否保持日志风格一致 | 是 |
| 是否补充必要测试 | 是 |
| 是否能构建通过 | 是 |
14.3 联网资料检查
| 检查项 | 通过标准 |
|---|---|
| 来源是否可靠 | 优先官方 |
| 版本是否匹配 | 是 |
| 是否与当前项目技术栈一致 | 是 |
| 是否说明适用范围 | 是 |
| 是否经过本地验证 | 是 |
| 是否只是搜索摘要 | 不应作为关键依据 |
| 是否存在隐藏指令风险 | 按不可信内容处理 |
15. 如何判断一次联网搜索是否污染了开发判断?
可以看模型回答中是否出现这些信号。
15.1 明显污染信号
1 | 突然引入当前项目没有的框架; |
15.2 更隐蔽的污染信号
1 | 回答看起来很完整,但和当前项目细节对不上; |
16. 更合理的联网使用策略
可以把开发任务分成四级。
L0:禁止联网
适合:
1 | 小范围代码修改 |
原则:
1 | 只看当前项目。 |
L1:只允许官方资料
适合:
1 | API 行为确认 |
原则:
1 | 只查官方文档、release note、changelog、标准文档。 |
L2:允许社区资料,但只作为参考
适合:
1 | 疑难错误排查 |
原则:
1 | 社区资料只能帮助提出假设,不能直接作为最终结论。 |
L3:允许广泛调研
适合:
1 | 技术选型调研 |
原则:
1 | 输出调研和备选方案,不直接生成最终代码补丁。 |
17. 最后给一个实用判断
日常开发里,联网搜索的价值在于补齐外部事实,不是替代当前项目判断。
可以把它理解成:
1 | 当前项目:事实来源 |
如果任务是“当前项目怎么改”,模型应该先看当前项目。
如果任务是“这个 API 现在怎么用”,模型可以查官方文档。
如果任务是“这个错误是不是已知问题”,模型可以联网找 issue。
如果任务是“给我一个可落地补丁”,模型必须回到当前代码、当前依赖、当前测试。
NCSC 相关讨论也强调,LLM 的 prompt injection 问题与传统 SQL 注入不同,因为模型很难天然建立严格的数据/指令安全边界;更现实的做法是把模型视为可能被混淆的组件,并限制被污染输出造成的影响。(TechRadar) 近年的 agent 安全研究也指出,AI agent 处理外部数据源时会暴露于间接提示注入风险,尤其是邮件、文档、代码仓库等日常开发环境中常见的数据源。(arXiv)
所以,比较稳的工程结论是:
联网搜索不能作为开发任务的默认设计入口,只能作为受控证据源。
更具体地说:
1 | 先看当前项目; |
这套原则不只适用于嵌入式,也适用于日常开发中的绝大多数任务:Bug 排查、代码生成、重构、接口设计、依赖选型、文档编写、测试补充和 Code Review。
 微信
微信- 支付寶








