autogen_parameter_manager:面向固件产品参数的生成式管理软件包
- 仓库地址: https://github.com/wdfk-prog/parameters

@[toc]
推荐判断
在嵌入式产品中,参数管理通常会从几个配置变量开始。早期代码里直接定义全局变量,或者在某个模块中保存默认值,短期内成本很低。项目继续推进后,参数会进入更多流程:生产标定需要写入校准值,现场调试需要临时修改阈值,上位机需要读取和展示配置,售后脚本需要批量检查状态,固件升级还要考虑旧版本已经保存的数据是否仍然可用。
到这个阶段,真正需要维护的已经不是单个变量,而是一组产品参数的长期接口。每个参数都可能同时包含外部 ID、类型、默认值、最小值、最大值、单位、说明、读写属性、持久化标记和版本兼容关系。只要这些信息分散在协议代码、shell 命令、业务模块和存储代码中,后续迭代就容易出现规则不一致。
autogen_parameter_manager 适合用于这类固件项目。它把参数表作为事实源,生成固件侧需要的参数定义、ID 映射、静态布局和摘要信息;运行时再基于这些生成数据提供类型化访问、范围和访问属性检查、回调机制、MSH 调试入口,以及可选的 NVM 持久化能力。它的价值主要体现在一致性和可维护性:同一批参数规则被业务代码、调试命令、上位机协议和持久化路径共同使用。
如果项目中只有少量内部变量,参数不会暴露给外部工具,也没有掉电保存和版本兼容压力,简单封装通常已经够用。若参数已经进入产测、上位机、售后或远程配置流程,并且需要长期保持 ID、类型、范围和保存规则稳定,那么引入集中式参数管理器的收益会更明显。
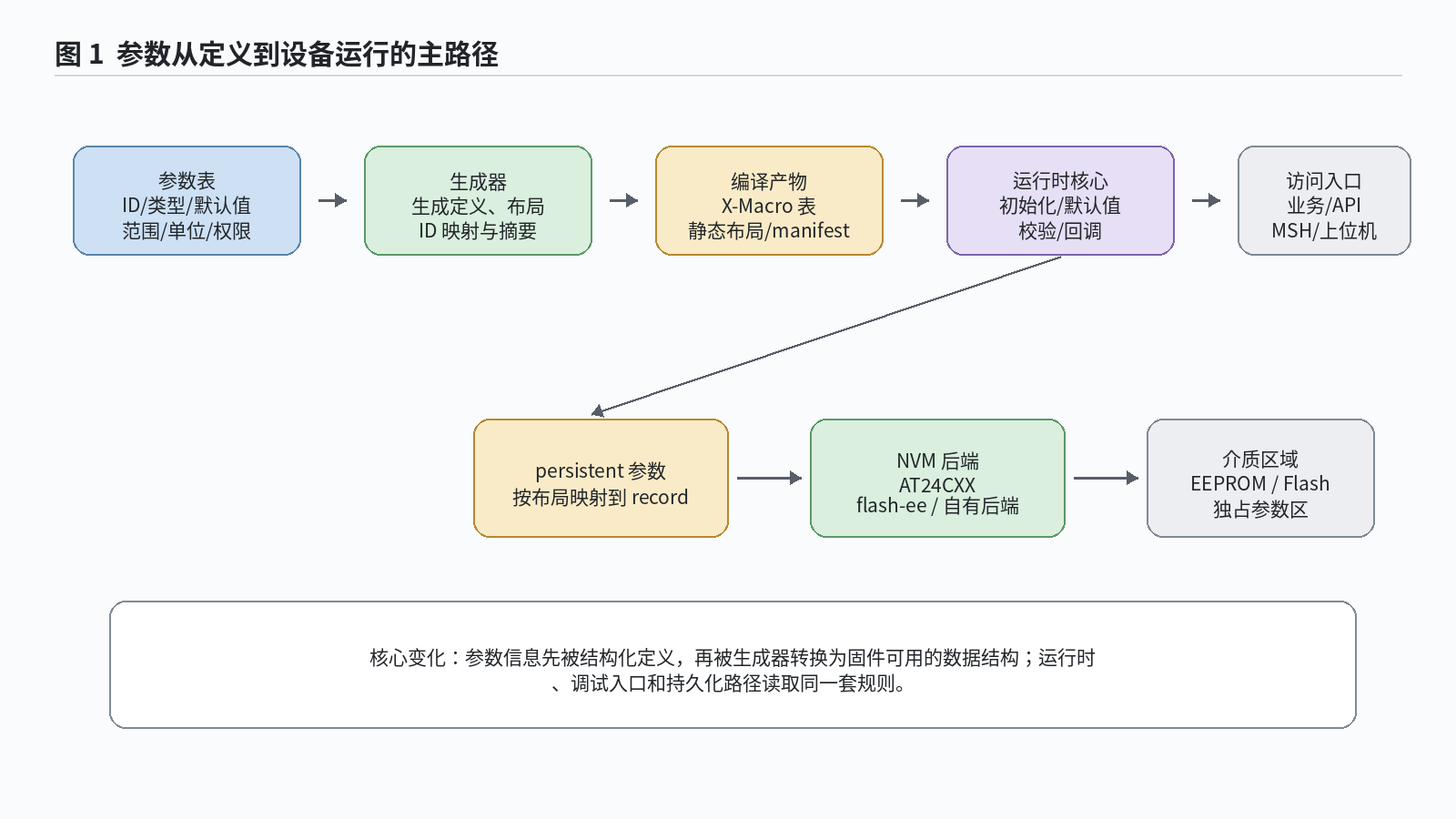
图:参数定义、生成代码、运行时访问和可选持久化之间的主路径
哪些场景更需要这类参数管理器
参数入口越来越多
一个常见变化是业务模块先需要参数,随后 MSH、产测工具、上位机协议和售后脚本也开始访问同一批数据。入口增加后,问题不在于是否能读写,而在于每个入口是否执行相同的规则。若协议层有一份范围表,shell 命令中又手写一份解析规则,业务代码再直接赋值,后续很容易出现某个入口允许写入异常值、某个入口看不到最新单位或描述、某个入口忘记同步新参数的问题。
autogen_parameter_manager 的思路是让入口不同、规则相同。业务代码可以使用生成枚举和类型化 API;外部工具可以按稳定 ID 读写;MSH 可以在板端查看当前值、默认值、范围、单位和持久化状态;NVM 只处理参数表中声明为 persistent 的项。各入口只负责自己的交互形式,参数规则由同一套生成数据和运行时路径提供。
参数 ID 已经成为协议的一部分
在纯固件内部,变量名、枚举顺序或数组下标都可以重构。外部工具开始参与后,参数 ID 就会变成产品接口的一部分。产测软件、上位机、售后脚本和远程配置流程通常不会跟随固件内部重构同步升级,因此外部 ID 的稳定性会直接影响兼容性。
该软件包使用 ID lock 和生成后的 ID 映射维护外部 ID。源码中还提供静态 ID hash map,把外部 ID 映射到内部参数编号,减少按 ID 查找时的线性扫描。参数数量增加后,这种路径有两个实际价值:一是读写查找开销更可控;二是 ID 或 hash 冲突可以更早暴露,而不是在现场通信时才表现为读写错误。
参数写入需要统一校验
对真实设备来说,写参数很少只是赋值。温度阈值、保护电流、采样周期、滤波系数、通信地址、校准值等都可能有范围限制;某些参数只允许产测或维护角色写入;某些参数在设备运行状态下不能修改;某些参数写入后还需要通知业务模块重新加载配置。
软件包的普通 setter 路径把这些动作串在一起:初始化检查、类型检查、范围和访问属性检查、运行时 validation callback、实时存储更新,以及 change callback 派发。这样做可以减少各入口重复编写判断逻辑,也能让审查重点集中在参数表和回调策略上,而不是分散到多个命令和协议处理函数中。
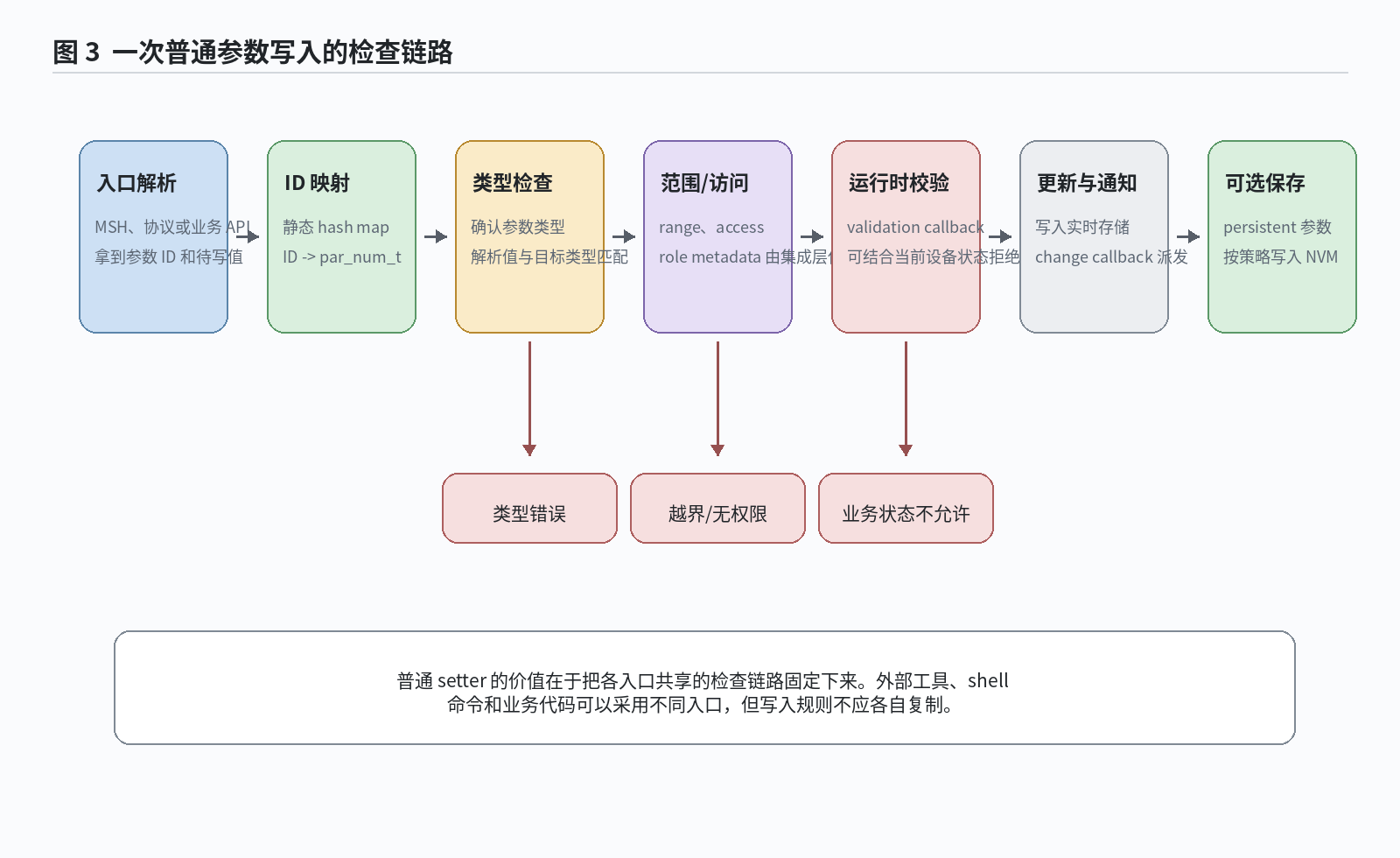
图:普通参数写入从入口解析到校验、更新和可选保存的链路
持久化需要随参数版本演进
参数掉电保存往往在项目后期变复杂。早期可能只保存几个阈值;后续会出现参数增删、类型变化、默认值调整、对象参数扩展、布局变化以及旧设备升级后的数据复用问题。如果存储层只看到一组 key 或一段裸数据,应用层就必须额外维护“哪些数据仍然可解释”的判断逻辑。
autogen_parameter_manager 把持久化限定在参数模型内部:只有参数表中声明为 persistent 的参数才进入 NVM 路径;table-ID 摘要把 schema version、布局、persistent 参数数量、顺序、类型等信息纳入兼容判断;不同 scalar record layout 可以在空间占用、自描述能力和升级诊断之间选择。对于 EEPROM 或小 Flash 分区,这种显式布局比临时拼装结构体更容易审查。
参数需要被工具理解
很多项目会在上位机或产测工具里再维护一份参数说明,用于显示名称、单位、范围和读写权限。短期看这能快速出界面,长期看会形成两个事实源:固件里的真实范围和工具里的显示范围可能不一致,固件新增参数后工具侧漏更新,工具侧仍使用已经废弃的 ID。
软件包支持 name、unit、description、access、persistent、read roles、write roles 等元数据,并能通过 MSH info / json 路径输出。工具侧可以围绕这些元数据生成显示项和校验项,减少重复维护说明表的需求。
总体架构:参数模型和存储后端分开
从源码结构看,这个软件包把参数定义、生成产物、运行时核心、移植层和可选 NVM 后端分成不同层级。参数表和生成器负责把产品参数固化为可编译的数据;运行时核心负责类型化访问、ID 映射、校验和回调;NVM core 决定 persistent 参数如何映射为记录;具体后端处理 EEPROM、Flash、FAL 分区或产品自有存储接口。
这种拆分对嵌入式项目比较重要。参数语义不应落到 Flash 擦写代码里,Flash 后端也不应理解业务参数的单位、范围和权限。职责边界明确后,后续更换存储介质、调整布局或新增调试入口时,参数表本身仍然可以保持稳定。
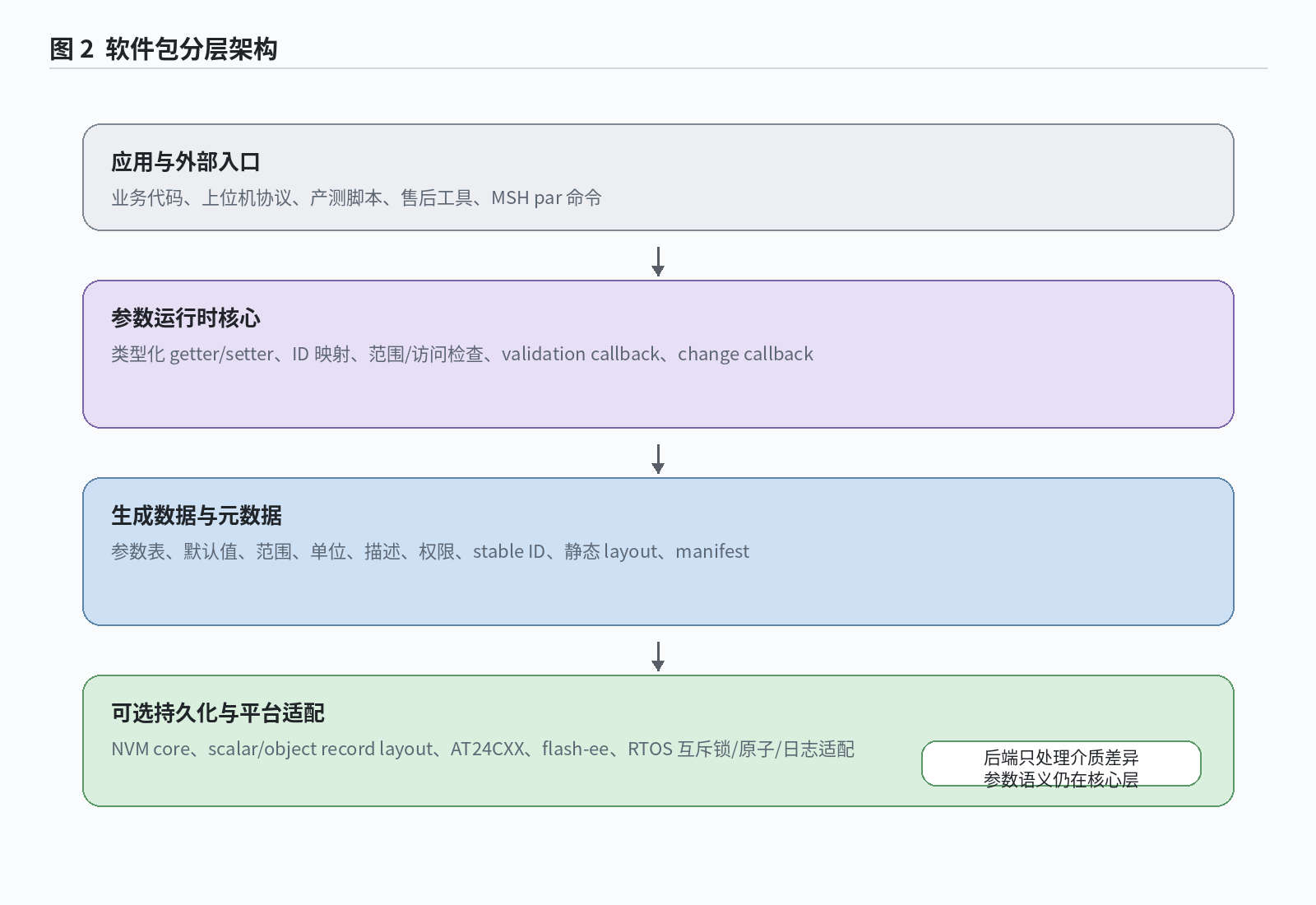
图:软件包分层结构与职责边界
| 层级 | 负责内容 | 带来的效果 |
|---|---|---|
| 参数表与生成器 | 维护参数行、ID、默认值、范围、单位、说明、访问属性和持久化意图,并生成 C 侧数据。 | 把参数规则集中到一个事实源,减少 enum、默认值、协议 ID 和存储映射分散维护。 |
| 运行时核心 | 初始化、默认值加载、类型化访问、ID 查找、范围/访问检查、validation 和 change callback。 | 让业务、MSH 和协议入口共享同一套访问规则。 |
| 元数据接口 | 提供 name、unit、description、type、range、access、persistent、role metadata 等查询。 | 便于板端调试、上位机展示、产测脚本和售后工具复用。 |
| NVM core | 只处理 persistent 参数,按布局把运行时值映射到 NVM record。 | 保存边界清楚,版本演进时可以基于摘要和布局判断兼容性。 |
| 存储后端 | 处理 EEPROM/Flash/FAL 或其他介质的读写、擦除、恢复和平台差异。 | 参数模型不绑定单一介质,后端可以按硬件条件替换。 |
主要优势
参数定义集中,生成代码减少重复维护
参数表包含枚举名、外部 ID、类型、默认值、范围、单位、访问属性、持久化标记和描述信息。生成器把这些信息转换为 C 侧编译产物,包括 X-Macro 参数表、静态布局、ID 映射、生成摘要和 manifest。
这类方式适合参数长期演进的产品。新增或修改参数时,核心信息集中在参数表中维护,生成产物再被运行时、调试命令和外部工具共同使用。相比在多个 C 文件中分别维护 enum、默认值、范围、协议 ID 和 NVM 映射,集中定义更容易审查,也更容易在本地检查或自动化检查中发现表结构问题。
范围、权限和回调在统一路径执行
软件包支持范围检查、访问属性、read/write roles 元数据、运行时 validation callback 和 change callback。普通写入路径不会直接把输入值写进存储,而是先完成类型和边界处理,再进入可选的业务校验和变更通知。
这对上位机联调、产测流程和现场维护尤其有用。工具侧只需要按参数 ID 调用统一 API,不需要复制所有参数范围和权限规则。即使协议入口、MSH 入口和业务入口不同,最终仍然可以使用同一套参数规则。
MSH 工具降低板端排查成本
源码中的 port/par_shell_tool.c 提供 par 命令。该命令围绕参数表工作,可用于查看参数信息、读取和设置标量参数、恢复默认值、保存 persistent 参数、清理并重写受管理的 NVM 区域,以及导出 JSON 格式信息。
| 子命令 | 用途 |
|---|---|
par info |
查看参数 ID、名称、当前值、默认值、范围、单位、类型、访问属性、持久化标记和描述。 |
par get <id> |
按外部 ID 读取参数值。 |
par set <id> <value> |
按外部 ID 写入标量参数,并经过解析、类型和访问相关检查。 |
par def <id> / par def_all |
恢复单个或全部参数默认值。 |
par save [id] |
保存全部 persistent 参数或指定参数到 NVM。 |
par save_clean |
清理并重写软件包管理的 NVM 区域。 |
par json |
导出机器可读的参数信息,便于脚本或上位机联调。 |
MSH 的价值不只是“能在命令行改参数”。更关键的是它可以在设备现场直接确认参数 ID、当前值、默认值、范围、单位、访问属性和持久化状态。当上位机显示、设备行为和保存结果不一致时,板端命令能快速判断问题出在协议转换、参数规则、运行时值还是 NVM 保存路径。
静态 ID hash map 改善按 ID 查找路径
外部工具通常按参数 ID 访问,而固件内部更适合使用连续编号或生成枚举。软件包中的静态 ID hash map 把外部 ID 映射到内部 par_num_t,避免每次读写都遍历完整参数表。
对于参数数量较多、上位机批量读取或周期读取的产品,这种设计能降低查找路径的固定开销。更重要的是,hash bucket 冲突会被提前处理,ID 配置错误不需要等到设备运行后才暴露。
NVM 多布局便于在空间和兼容性之间取舍
参数持久化并不只有一种格式。软件包在 parameters/src/nvm/scalar/layout/ 下提供多种 scalar record layout,用于在记录自描述能力、空间占用和版本兼容之间取舍。
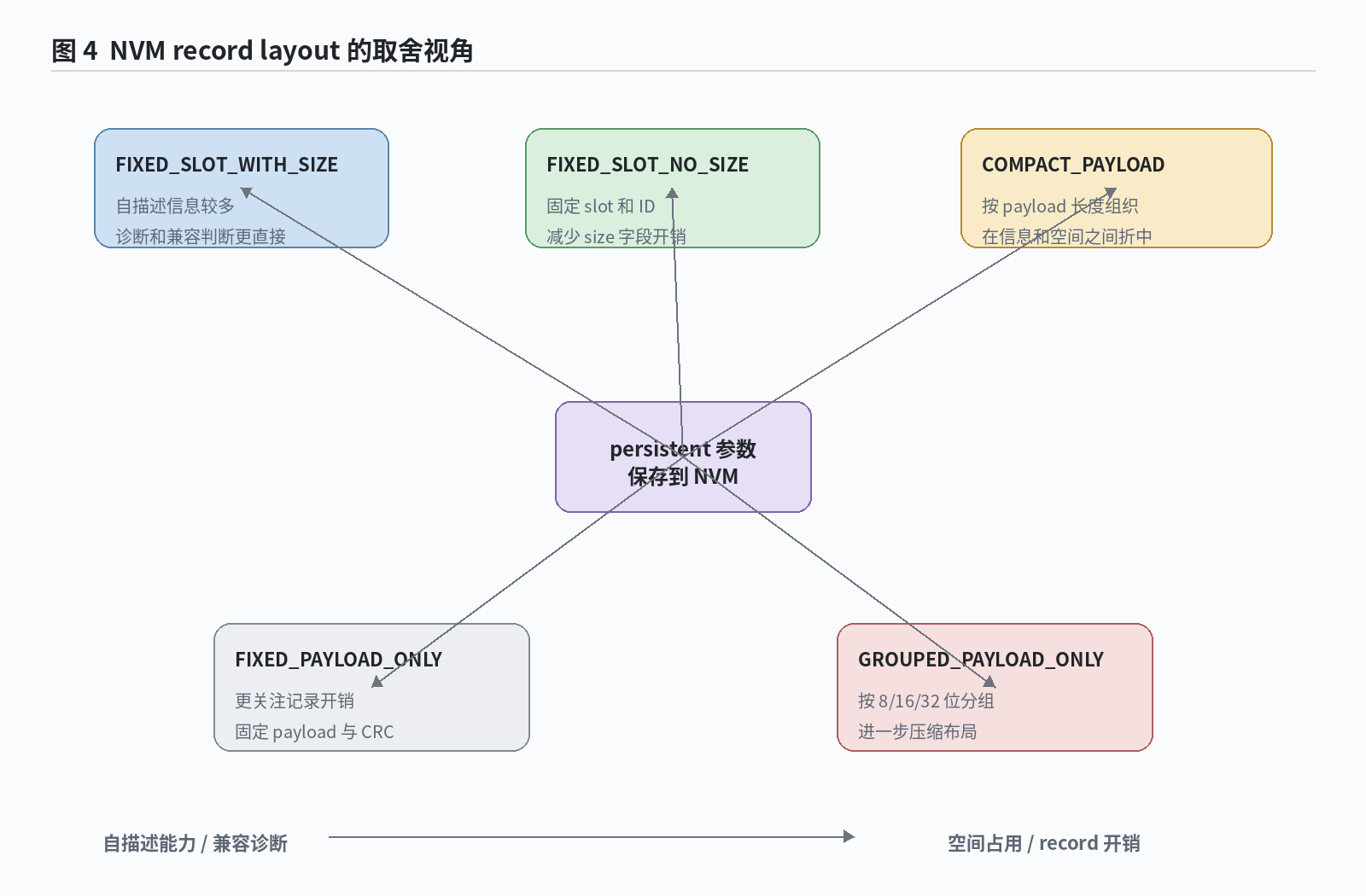
图:NVM scalar record layout 的取舍关系
| NVM record layout | 适用取向 |
|---|---|
FIXED_SLOT_WITH_SIZE |
记录包含更多自描述信息,便于诊断和兼容判断。 |
FIXED_SLOT_NO_SIZE |
保留固定 slot 和 ID,减少 size 字段带来的额外开销。 |
COMPACT_PAYLOAD |
按 payload 长度组织记录,在信息量和空间占用之间折中。 |
FIXED_PAYLOAD_ONLY |
更关注记录开销,只保存固定 payload 与 CRC。 |
GROUPED_PAYLOAD_ONLY |
按 8/16/32 位 payload 分组,进一步压缩布局。 |
如果目标介质是外部 EEPROM 或很小的 Flash 分区,记录头开销会直接影响可保存参数数量。如果项目更看重升级诊断和兼容判断,保留 ID、size 等信息又更有利。该软件包把这些取舍显式化,避免持久化格式变成难以解释的私有裸数据。
对象参数覆盖小段结构化数据
除 U8/I8/U16/I16/U32/I32 和可选 F32 等标量类型外,软件包还支持 STR、BYTES、ARR_U8、ARR_U16、ARR_U32 等对象参数。对象参数具有长度、容量、默认值和对象 API,适合保存设备标签、小段校准数据、查找表、控制曲线或协议相关固定数组。
对象参数不能替代文件系统或大容量数据库,但它可以覆盖参数系统中常见的小对象场景。相比把字符串、二进制块或数组塞进不透明指针中处理,固定容量和类型化 API 更容易做边界检查和持久化审查。
元数据可以被固件和工具共同使用
name、unit、description、access、persistent、read roles、write roles 等信息不只用于阅读参数表。它们可以通过 API 或 MSH 输出给板端命令、上位机、产测脚本和售后工具。
这能减少工具侧重复维护说明表。比如上位机可以根据参数元数据展示单位和范围,产测脚本可以按 access 和 persistent 属性筛选需要写入或核对的项,售后工具可以导出参数快照用于问题复现。
功能可裁剪,适合不同阶段逐步启用
功能开关覆盖类型、元数据、范围、ID、运行时表检查、validation callback、change callback、对象参数、NVM、MSH 子命令和 JSON 输出。小型项目可以只保留标量访问和必要元数据;需要完整调试与持久化能力的项目再启用对象、MSH、JSON 和 NVM。
这种裁剪方式适合资源分层明显的 MCU 项目。它允许软件包从参数表和类型化 API 起步,再按产品阶段逐步打开调试、权限和持久化能力。
测试材料覆盖运行时和持久化路径
仓库中包含运行时测试、生成器测试、NVM 手动测试和 schema evolution 相关测试文档。对参数管理器来说,测试材料的意义在于把“参数表是否能生成、setter 是否执行校验、NVM 是否能恢复、schema 变化后数据是否可接受”这些问题前移到开发和验收阶段。
这类测试不会消除具体硬件上的掉电和擦写验证工作,但能给软件包能力边界提供更明确的验证入口。对于已经进入维护期的嵌入式产品,这比只依赖现场调试更可控。
典型使用链路
一个比较完整的使用链路可以分为四段。第一段是维护参数表,明确参数 ID、类型、默认值、范围、单位、访问属性和持久化意图。第二段是生成固件侧代码,让运行时、ID 映射、静态布局和 manifest 使用同一份输入。第三段是业务和调试入口通过类型化 API、外部 ID 或 MSH 命令访问参数。第四段是对 persistent 参数执行保存和恢复,并在固件版本变化时依据 table-ID 和布局信息判断数据是否可以复用。
| 阶段 | 主要动作 | 关注点 |
|---|---|---|
| 定义阶段 | 维护参数行、ID、类型、默认值、范围、单位、说明、权限和 persistent 标记。 | 参数是否表达完整,外部 ID 是否稳定,元数据是否足够给工具复用。 |
| 生成阶段 | 生成 X-Macro 表、静态布局、ID 映射、摘要和 manifest。 | 生成结果是否可审查,ID/hash 是否冲突,布局是否符合持久化预期。 |
| 运行阶段 | 业务代码、MSH 或协议入口读写参数。 | 写入是否经过类型、范围、访问、validation 和 change callback 链路。 |
| 保存阶段 | persistent 参数写入 NVM,启动时恢复。 | record layout、table-ID、schema version 和后端恢复策略是否匹配产品需求。 |
这个链路的重点是让参数信息只维护一次。参数数量越多、入口越多、版本越多,这种单一事实源的价值越明显。
与 FlashDB、EasyFlash 的区别
FlashDB、EasyFlash 和 autogen_parameter_manager 都可能出现在“参数保存”这个话题中,但它们解决的问题处在不同层级。FlashDB 面向 Flash 提供 KVDB 和 TSDB 数据库模式,适合保存 key-value、blob、时序记录、历史采样、告警和事件数据。EasyFlash 面向 Flash 常见应用,提供 ENV、IAP、Log 等能力,适合环境变量、在线升级数据和 Flash 日志。
autogen_parameter_manager 关注的是固定产品参数的模型化管理:参数如何定义,如何生成 API 和 ID 映射,如何检查范围和访问属性,如何输出元数据,哪些参数进入持久化,以及参数版本变化后旧数据能否继续使用。它可以和底层存储库共存,但对外暴露的主要接口仍然是参数访问和参数元数据,而不是通用数据库 API。
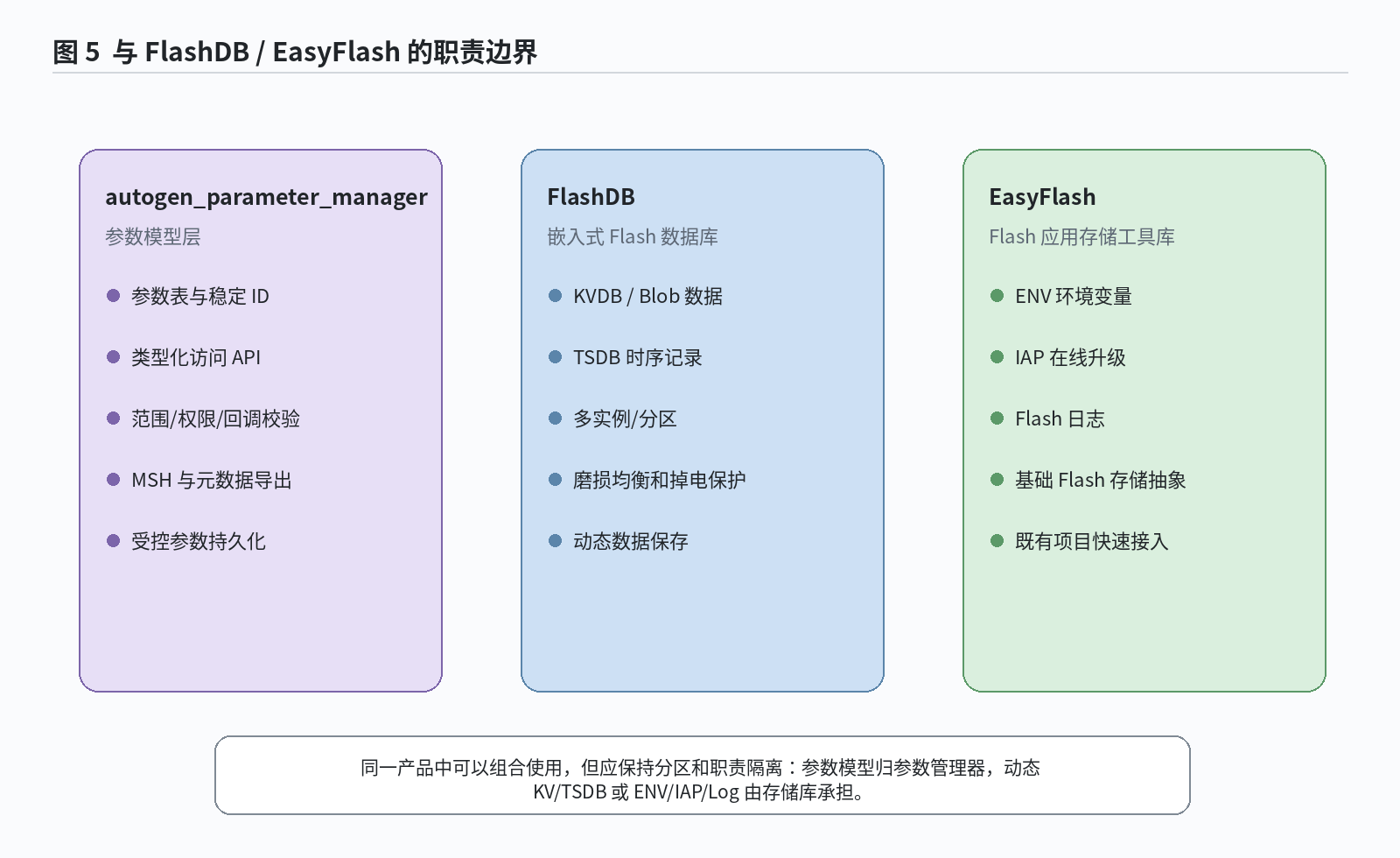
图:autogen_parameter_manager、FlashDB 和 EasyFlash 的职责边界
下表中 APM 指 autogen_parameter_manager。
| 维度 | APM | FlashDB | EasyFlash |
|---|---|---|---|
| 主要目标 | 固定产品参数 schema 的生成、访问、校验和可选持久化。 | Flash 上的 KVDB/TSDB 数据库。 | ENV、IAP、Log 等 Flash 应用能力。 |
| 数据模型 | 参数表、类型、默认值、范围、权限、稳定 ID 和元数据。 | key-value、blob、time-series record。 | 环境变量、升级数据和日志数据。 |
| 访问方式 | 生成枚举、外部 ID、类型化 API、MSH 命令和元数据 API。 | 数据库实例、KV API 和 TSDB API。 | ENV/IAP/Log API。 |
| 校验重点 | 范围、访问属性、role metadata、validation callback、change callback、表一致性。 | 数据库可靠性、磨损均衡、掉电保护、KV/TSDB 数据管理。 | Flash ENV/IAP/Log 的保存与管理。 |
| 持久化边界 | 只保存参数表中声明为 persistent 的参数。 | 数据库内数据由应用按 key 或 record 管理。 | ENV、IAP、Log 各自管理 Flash 数据。 |
| 更适合的数据 | 校准值、控制参数、通信参数、调试参数、生产参数。 | 用户配置、动态 KV、历史采样、告警和事件记录。 | 少量环境变量、升级数据、Flash 日志。 |
| 典型边界 | 不面向大量动态 key、长历史记录、日志流或 IAP 镜像。 | 不生成参数 API、参数元数据和访问规则。 | 不提供完整参数表生成、类型化 API 和复杂元数据模型。 |
选型时可以按问题类型判断。如果主要问题是动态数据保存、时序记录或事件历史,FlashDB 更匹配;如果项目已经依赖 EasyFlash 的 ENV/IAP/Log,并且需求集中在这些能力上,继续使用 EasyFlash 更直接;如果问题集中在固定产品参数的 ID、类型、范围、权限、调试、元数据和受控持久化,autogen_parameter_manager 的层级更接近需求。
作为软件包分享时可以强调的工程价值
- 参数定义集中,减少 enum、默认值、范围、单位、协议 ID 和持久化映射分散维护。
- 生成代码和静态布局降低手写参数表的重复工作,也便于审查参数表结构。
- 稳定外部 ID 和静态 hash map 让上位机、MSH 和持久化 record 使用一致的参数身份。
- 范围、访问属性、运行时校验和变更回调在统一路径执行,降低各入口规则不一致的风险。
- MSH
par命令覆盖查看、读取、写入、恢复默认值、保存和 JSON 导出,适合板端排查和联调。 - NVM 提供多种 scalar record layout,可在自描述能力、空间占用和版本兼容之间选择。
- 支持字符串、二进制块和固定数组等对象参数,覆盖小段结构化参数数据。
- 元数据可被固件、板端命令、上位机、产测脚本和售后工具共同使用。
- 功能可裁剪,可以从基本标量参数逐步扩展到调试、权限、对象参数和持久化。
- 仓库包含运行时、生成器、NVM 和 schema evolution 相关测试材料,有助于把参数演进风险前移。
这类软件包适合被推荐给已经进入工程化维护阶段的嵌入式产品。它解决的不是某一个 API 的便利性,而是参数从定义、访问、校验、调试、保存到版本演进的一致性问题。参数规模越大,外部工具越多,版本生命周期越长,统一参数模型带来的收益越明显。
参考资料
- wdfk-prog/parameters repository: https://github.com/wdfk-prog/parameters
- FlashDB repository: https://github.com/armink/FlashDB
- EasyFlash repository: https://github.com/armink/EasyFlash
- EasyFlash documentation: https://armink.github.io/EasyFlash/
- 源码与文档:
README.zh-CN.md、parameters/docs/*.zh-CN.md、port/par_shell_tool.c、parameters/src/nvm/、parameters/src/def/、parameters/tools/pargen.py。
- 微信
- 支付寶








